ビジネス
【連載】HAYST法のこれまでとこれから:「HAYST法」誕生(第2回)

HAYST法の概要
前回は、T統括部長(配下に500人くらいの社員を抱える上席)に実験計画法の達人である吉澤正孝氏を紹介していただいたところまで書きました。
吉澤氏(以降は、普段どおり吉澤さんと記載します)は、デミング賞委員会の委員をしたり、品質工学会の副会長を務めたり、2005年に日本品質管理学会から品質管理推進功労賞を受賞していたりしている、品質関係の有識者です。
なお、吉澤さんはソフトウェアの専門家ではありません。プログラムを1行も書いたことがありませんし(マクロくらいはあるかも?)、ソフトウェアテストも一切したことがありません。ソフトウェアテストの本は、『はじめて学ぶソフトウェアのテスト技法』(リー・コープランド著)を読んだだけと聞いた記憶があります。そのときは、良い本をチョイスされたなあと思いました。
吉澤さんとは出会って数年後の2005年から一緒に、ソフトウェアテストのコンサルティングをしました。そのときに、吉澤さんが、ソフトウェアの専門家が困っていることを次々と品質管理技術で解決している様子に舌を巻きました。コンサルティングに必要な能力の一つに「もつれにもつれた糸のようになってしまった現状を解きほぐす力」があると思うのですが、それにはソフトウェアの専門知識は不要なのだなと思いました。私の(勝手に弟子入りしている)師匠の一人です。
私がご指導いただいた2000年頃は50歳を少し超えた辺りで、会社では、「何か困ったことがあったら吉澤さんに相談したらいい」といわれていました。今年の夏に喜寿を迎えられるそうですが、今も品質工学の体系化に取り組み、また、企業数社の指導を続けていらっしゃいます。スーパーマンですね。
さて、HAYST法の概要についてです。HAYST法は、実験計画法で使用する直交表にソフトウェアの機能を割り付けて、少ないテスト回数で広く機能の組合わせをテストするテスト技法の一つです。英語では、“Highly Accelerated and Yield Software Testing”と書きます。
ちなみに上記のスペルは、後付けです。名付け親の吉澤さんによれば、HAYST法に関わった人の名前の頭文字をつなげたものだそうです。Hセンター長、秋山(筆者)、吉澤さんと山本さん(の2人のYでYs)、T統括部長(もしくは品質工学の創始者である田口玄一博士のT)です。それをヘイスト(haste:迅速)の語感に当てたとのことです。
なお、hasteはファイナルファンタジーというRPGの魔法(戦闘時の速度が速くなる魔法)のヘイストと同じです(hasteの発音記号はhéistで、子音のstは聴き取れず、hasteは「ヘイ」としか聞こえません。HAYST法のほうは日本語なので、普通にヘイストホウと読んでください)。
HAYST法がどのようなテスト技法か、具体的に、直交表にソフトウェアの機能を割り付ける例で説明します。前回の「用紙サイズ×用紙方向×面付け」であれば、まず、因子(Factor)と水準(Level)を表にまとめます(この表を「FL表」といいます)。

このように、因子(機能)と水準(機能の中で取りうる値)を挙げて、後は、適切なサイズの直交表(下表はL4直交表)に割り付けることで、組合わせテストを減らそうというテスト技法がHAYST法です。
※因子のことをパラメータ(P:parameter)、水準のことを値(V:value)と呼ぶ人もいらっしゃいますが、以降では、因子と水準で記載を統一します(ハードウェアや環境などの要因のことをパラメータと呼ぶのは、しっくりこないためです)。
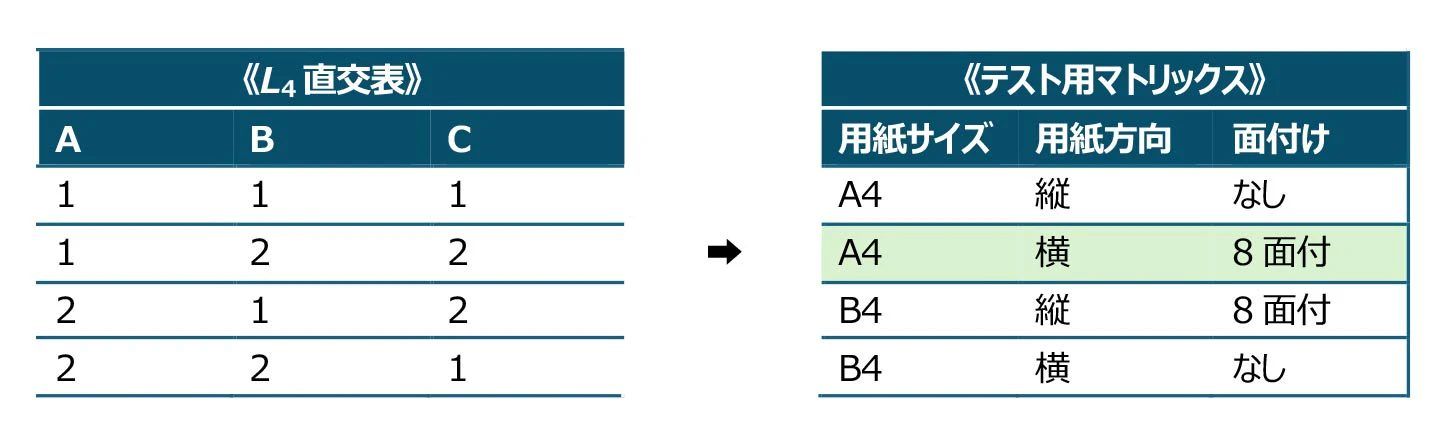
上記のL4直交表で言えば、全組合せは、2³で8のところ、4通りに半減しています。直交表が大きくなれば、組合わせテスト数の削減効果も大きくなります。
例えば、L32では31個の因子をわずか32行の表に収めてしまいます。31個の2水準因子を全て組み合わせると、その組合わせ数は、2³¹=2,147,483,648となります。これを32個の組合わせテストで済ませる方法です。
直交表の仕組みや禁則回避方法の詳しい説明といった話は書籍等(※1)をご覧ください。
(※1) HAYST法に関する書籍は、『ソフトウェアテストHAYST法入門』(日科技連出版社、2007)と『事例とツ-ルで学ぶHAYST法』(日科技連出版社、2014)があります。ウェブでは、JaSST'18 Tohokuの資料が詳しく分かりやすいです。
上記の表についてよく見ると、年賀状に4コママンガをプリントできない不具合の原因である、A4用紙で横向きの8ページ物を8面付けする条件が出ています(右表の緑色行)。
用紙サイズはもっと種類が多いですし、出力側の用紙サイズも種類が多いので、実際のテスト用マトリックスはずっと大きなものになるのですが、それでもHAYST法では64件程度のテストケースで組合わせテストを終えてしまいます。
HAYST法の効果に戸惑う
前回、開発者から「そんな使い方は想定外です」と言われたという話を書きました。そして、「もしも、そういう想定外の組合せのバグを見つけるために全組合せテストをしたら、いったい一体どれほどのテストが必要だと思っているんです?」とも言われたと書きました。
HAYST法を使用して直交表に機能を割り付ければ、組合わせテストは、どんなに因子が多くても64件のテストケースに抑えられ、それは実施可能なテスト数なのでテスト実行されます。
1分に200ページ以上プリントできる大型のプリンターのテストから、1分に10ページ程度の小型のプリンターのテストまで、会社で開発していたプリンターのテストに次々とHAYST法を適用していった結果、どのテストでも組合わせバグが見つかり、リリース後の想定外バグはゼロになりました。
この「想定外」の使い方の問題は解決され、その結果を、2003年の品質工学研究発表大会で発表しました。また、翌年のJaSST’04でも発表し、「ベストスピーカー賞(金賞)」を受賞しました。
ただし、当時の私は、この方法でプリンタードライバーの組合わせテスト件数の爆発を防止し、少ないテスト件数で効果が高いテストができることは分かったけれど、自分たちが何を解決しているのかについてはっきりと認識できず、常にモヤモヤしていました。
そんなことはお構いなしに、雑誌「日経コンピュータ」に取り上げられたこともあり、さまざまな企業から「うちでもHAYST法を使ってみたいので方法の指導とツールを譲っていただけないか」と会社に問い合わせが相次ぎました。
「弊社のお客様の助けとなるのならどんどんやりなさい」という経営トップからの指示もあり、コンサルティングという建付けで、吉澤さんと私は、半年に2社ほどの頻度で、さまざまな会社にHAYST法の技術を伝えていきました。
各社には隔週で訪問しました。半年間なので、全12回です。基本は12回でHAYST法を実践できるようにするので、後は社内展開をお願いするのですが、大きな会社では社内展開が難しいケースがあります。その場合は、この12回セットを何回か行うこともありました。
半年としたのは、半年あれば、仮にうまくいかなかったときにリカバリーできると考えたからです。教育とツールを渡し、短期で、実業務のコンサルティングをすれば、その後、お客様自身が実施してうまくいかなければ現場の使い方が悪いと逃げることができます。ですが、訪問先は自社のプリンターを購入いただいている大切なお客様です。効果が出たことを確認し、出ていなかったら石にかじりついても何とかしようと吉澤さんと話していました。
この活動スキームは2004年から10年くらい続きました。合計60社程度のテスト業務のコンサルティングをしたことは私の財産となりました。
こうして、社内のテストだけでなく、さまざまな業種のテストをHAYST法で実施し、どこでも組合せバグが減りテスト工数も減っているのを目の当たりにするうちに、先に書いた、自分たちが何を解決しているのかについてのモヤモヤは大きくなる一方でした。
「どうして、この方法でバグが見つかるのだろう」、「これまで想定外のバグはどうして見つからなかったのだろう」と。
想定外のバグについて考えた
そこで原点に戻って、「想定外のバグ」について考えてみました。その結果、想定外のバグは以下の2つの原因で発生していることが分かりました。
1.組合せの数が大きくなりテストしきれないと考え、小さな範囲に分けて、それぞれの範囲内で全組合せテストをしているため、範囲を超えた因子の組合せがテストされないから
2.組合せとは関係なく人間がソフトウェアを作る以上、うっかりミスは避けられないから
一つ目については、前回書いたとおり、組合せの数は爆発的に増えるからです。YouTubeにある『フカシギの数え方』という動画を見ると直感的に理解できると思います。
HAYST法では直交表を使用することで広く浅く網羅する方法を取っています。この「浅い網羅」で良いという点が組合わせテストの盲点でした。
次に、二つ目についてですが、こちらは、私がXの固定ポストにしている内容です。
人間である限り、うっかりミスをゼロにする方法はありません。ただし、うっかりミスは非常に発生頻度が低いので、打つ手はあります。同じ作業を並行して実施して結果を突き合せればよいのです。
簡単な例で考えてみます。「ありがとう」を「あるがとう」にうっかりタイプミスする確率を100回に1回とします。AさんとBさんに別々に「ありがとう」と書いてもらったのち、その結果を比較したら下表の4つの結果のどれかになります。
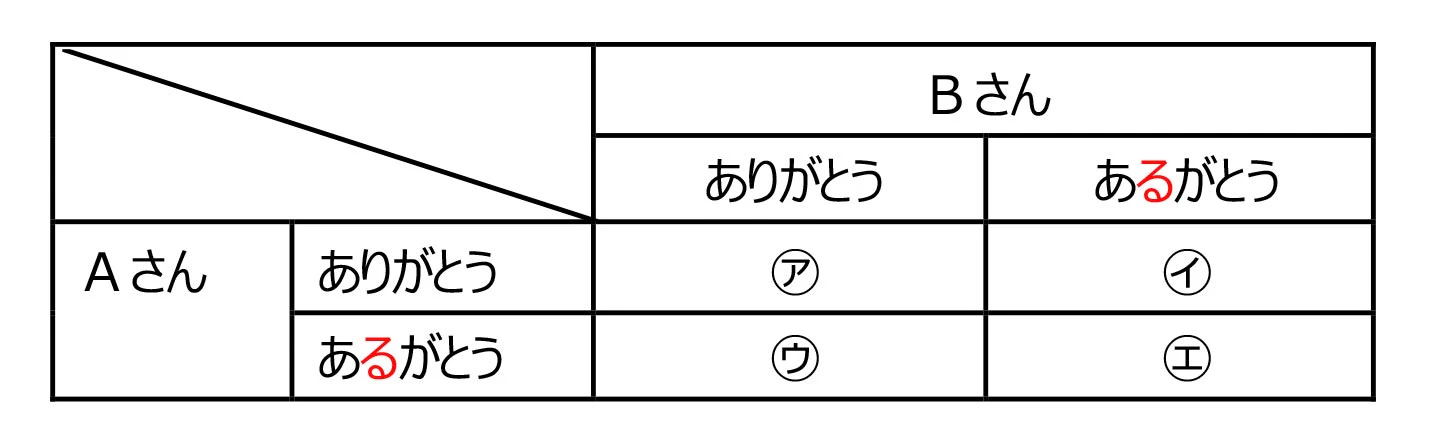
ここでAさんの結果を採用するときにBさんの結果を使うと、Aさんのタイプミスを発見できないのは、Bさんが同じように間違えた㋓のときだけだと分かります。
そもそも㋐は間違っていません。㋑と㋒についてはAさんとBさんの結果を突き合せれば、どちらかが間違っていることが分かります(インシデントとして報告して調査できます。調査した結果、㋑については間違えていない偽陽性と分かりますが、タイプミスの発見には関係ありません)。
Aさんのタイプミスを発見できないのは㋓のときとなります。さて、ここで㋓の発生確率を計算すると、(1/100)×(1/100)ですので1万分の1となります。100分の1のミスは1000行あったら10個のミスをしてしまうということですから、見過ごすわけにはいきません。しかし、1万分の1なら「仕方ない。ミスがあったら、そのときはそのときだ」とレジリエンス的な対応(問題が発生してから柔軟に対応する)で十分です。
実は、ソフトウェアテストはこの原理を使用しています。開発者Aが仕様書からプログラムを作り、テスターBが仕様書からテストケース(操作+期待結果)を作り、テストケースの操作をプログラムに対して実施して、その実施結果と期待結果を突き合せます。
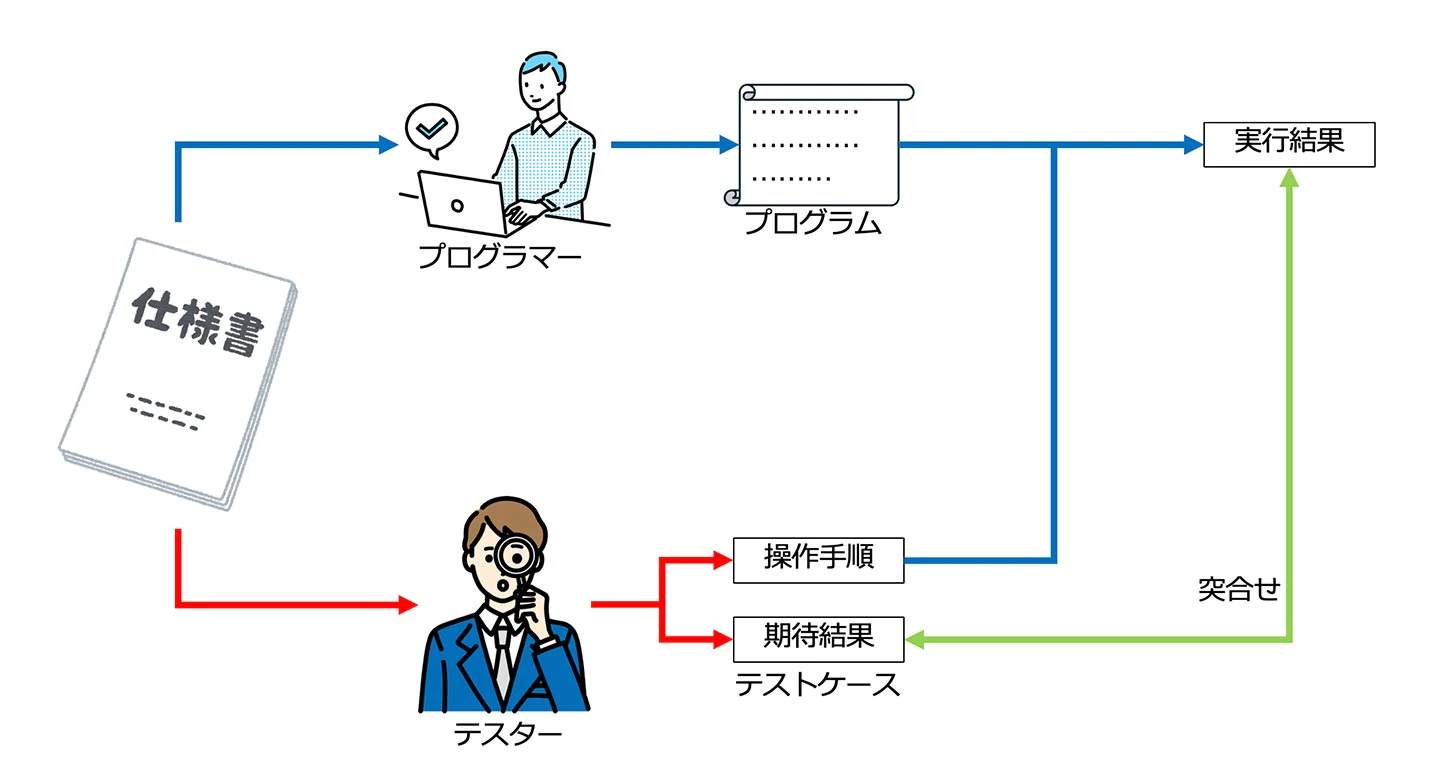
想定外のバグについてこのような方法で見つけていたということが分かり、私のモヤモヤは晴れたのでした。
この記事を書いた人

執筆
秋山浩一
株式会社日本ウィルテックソリューション ITコンサルタント。 大手事務機メーカーで36年間勤務し、内25年間、ソフトウェアテストや品質保証に携わる。現職では、CMMIのSEPGの一員としてプロセス改善を実施している。社外活動としてはNPO法人ASTERの理事としてテストセミナーの講師などを担当している。また、JSTQBステアリング委員。著書に『ソフトウェアテスト技法ドリル第2版』、『ソフトウェアテスト講義ノオト』、『事例とツールで学ぶHAYST法』などがある。博士(工学)。
この記事は面白かったですか?
今後の改善の参考にさせていただきます!





























































-portrait.webp)


























