Technical Information
生成AIの仕組みと使い方

生成AIは、高品質で専門性の高い画像や文章、プログラムなどを容易かつ高速に生成可能なことから、知的生産性の大幅な向上につながることが期待されています。本講演では、生成AIの仕組みと「ChatGPT」に代表される言語生成AIの使い方についてお話しします。
※この記事は、『ベリサーブ アカデミック イニシアティブ 2023』の講演内容を基にした内容です。

国立研究開発法人産業技術総合研究所 人工知能研究センター
招聘研究員
麻生 英樹 氏
生成AIの仕組み
■生成AIとは?
生成AIを一言で表現すると、「文章や音声、画像、動画などを人間のように生成するAI」ということになります。以前のAIの代表的なタスクは「認識・識別」で、入力された画像に、犬や猫などの映っているもののラベルを付ける、あるいは入力された文章を内容ごとに分類するというように、入力に対して出力される情報量が非常に少ないものでした。
一方、生成AIでは画像や文章を入力すると、それに対する出力も画像や文章で応答します。つまり、入力に合わせてより大きな情報量の出力を返すことが可能になっているのが特徴です。
■データ生成の仕組み
生成AIでは、大量の画像や文章のデータをシステムに与えて、そのデータの「確率分布」を学習します。確率分布は、ある入力を条件とした時に、次にどんな画像や文章が出現しやすいかの確率を示すものです。これを学習することで、入力に合ったデータをサンプリングし、新しい文章や画像を生成するという仕組みになっています。(図表1)
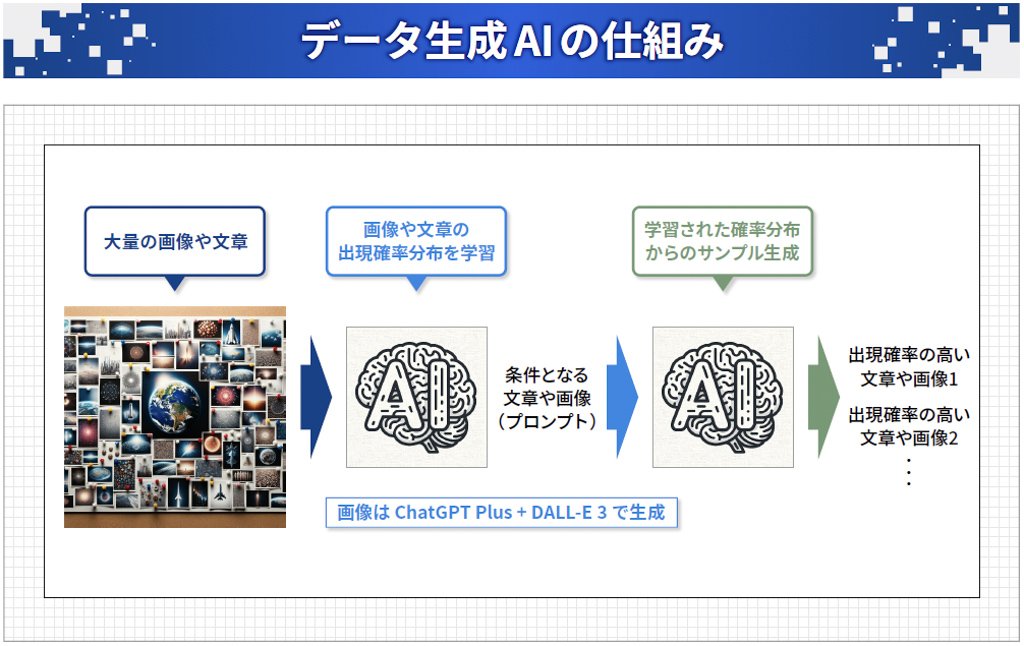
図表1:大量の画像や文章のデータから確率分布を学習し、条件に近いデータをサンプリングして文章や画像を生成する
・データの確率分布の学習
確率分布の学習は以下のプロセスで行われます。
学習用データ+学習モデル+学習アルゴリズム→学習済みモデル
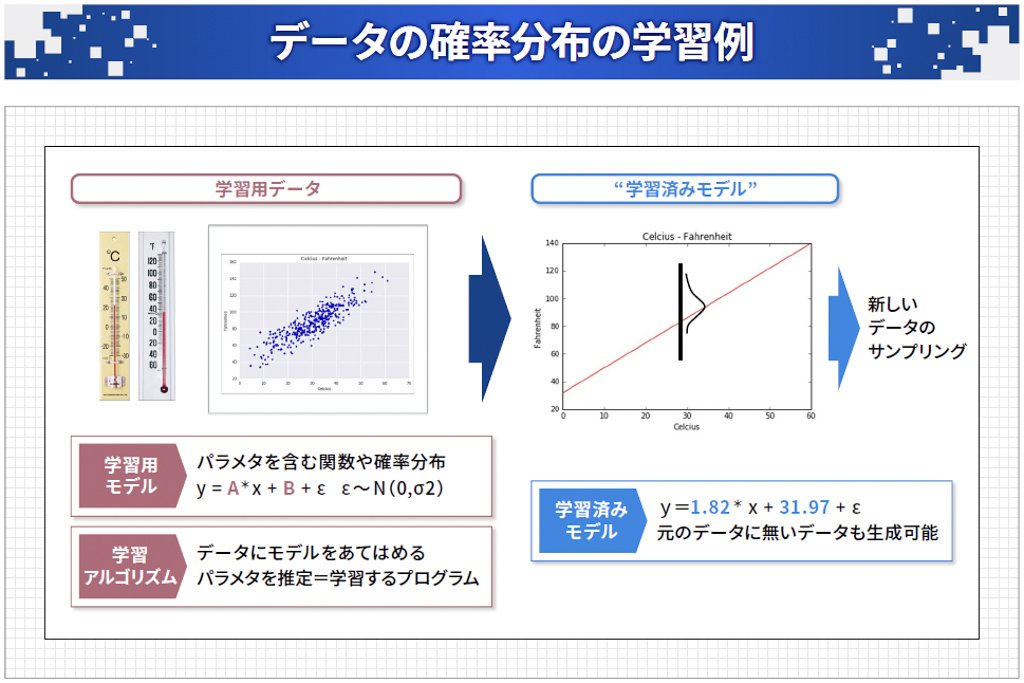
図表2は、「摂氏の温度を華氏の温度に変換するプログラム」の作成を基にした、確率分布の学習例です。「学習用データ」は摂氏を横軸(x)、華氏を縦軸(y)としてデータをプロットしたものです。次に「学習用モデル」ですが、ここではデータが直線に乗っているので「y=A*x+B+ε」という一次式をモデルとして使っています。そして、この式のパラメータであるAやBをデータに合わせて一番良い値に調節するのが「学習アルゴリズム」です。
こうして得られるのが右側の「学習済みモデル」で、直線の両側にデータが分布し、直線から離れるほどデータは出にくくなり、直線の上が一番出やすいという確率分布を学習したことになります。この学習済みモデルによって、新しいデータのサンプリングができるようになります。
丸山宏氏の機械学習利用促進勉強会資料を基に一部改変
図表2:「学習済みモデル」を得ることで新しいデータのサンプリングができる
・ディープニューラルネットワーク
ただし、ここで例示した確率分布で生成できるのは、xとy という2次元のごく単純なデータです。画像や文章の生成では、例えば100万画素の画像を生成する場合は100万次元となり、確率分布も非常に複雑になるため、学習は不可能と思われていました。これを打破したのがディープニューラルネットワークで、生成AIの実現に大きく貢献することになりました。
ディープニューラルネットワークは、人間の脳にある「ニューロン」と呼ばれる神経細胞をモデル化し、ネットワーク上で大量につないだ回路です。ニューロンには接続部分に全部パラメータが付いていて、例えば100万個のニューロンがあれば、パラメータの総数は数億個になります。これにより、大量のデータに対応する学習モデルを作ることができ、複雑な確率分布の学習が可能になりました。(図表3)
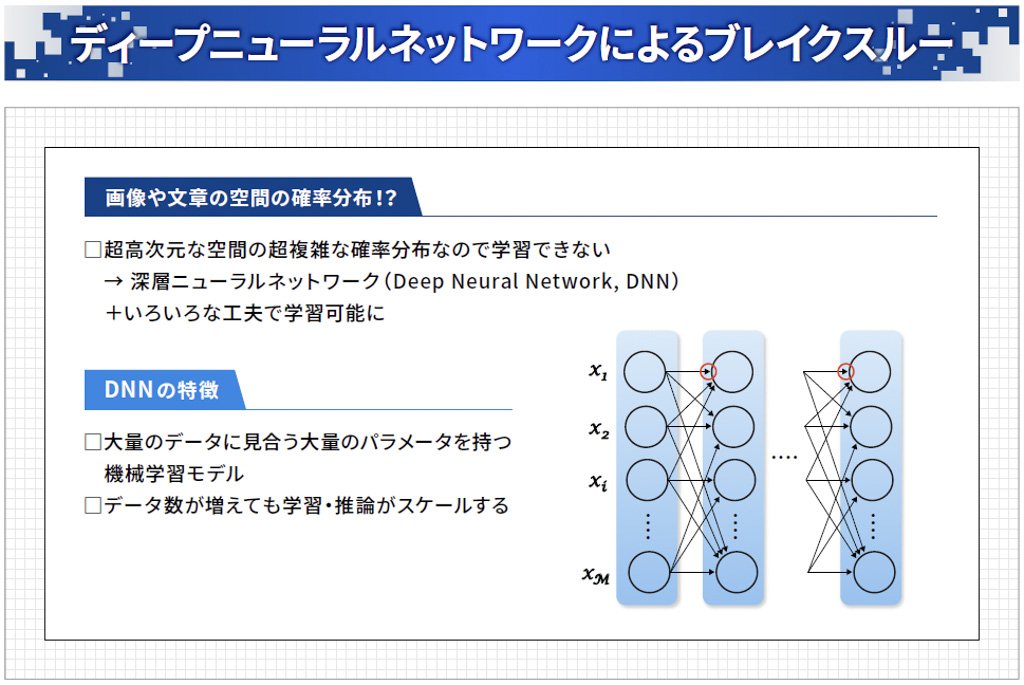
図表3:ディープニューラルネットワークにより複雑な確率分布の学習が可能になる
■文章生成AIの仕組み
文章の生成にも確率分布が使われています。文章は「単語の列」ですが、ある単語の列がどの程度人間の言葉として適切で、世の中に現れやすいかという確率分布を学習します。例えば、「日本の首都は東京、米国の首都は」という入力を条件とした場合、次に現れる単語として確率が高いのは何かを学習することになります。
ただ、文章にはいろいろな長さがあります。また「長距離依存」と呼ばれますが、例えば
太郎は次郎が買った三郎が書いた四郎が飼っている犬についての本を読んだ
という文章では、最後の「読んだ」の主語は「太郎」です。つまり文頭まで戻る必要があり、近くの単語を見るだけでは理解できません。さらに単語の1つ1つが意味を持っていて、そこから文章全体の意味が構成されます。この性質があるからこそ、初見の文章でも意味が理解できるわけです。
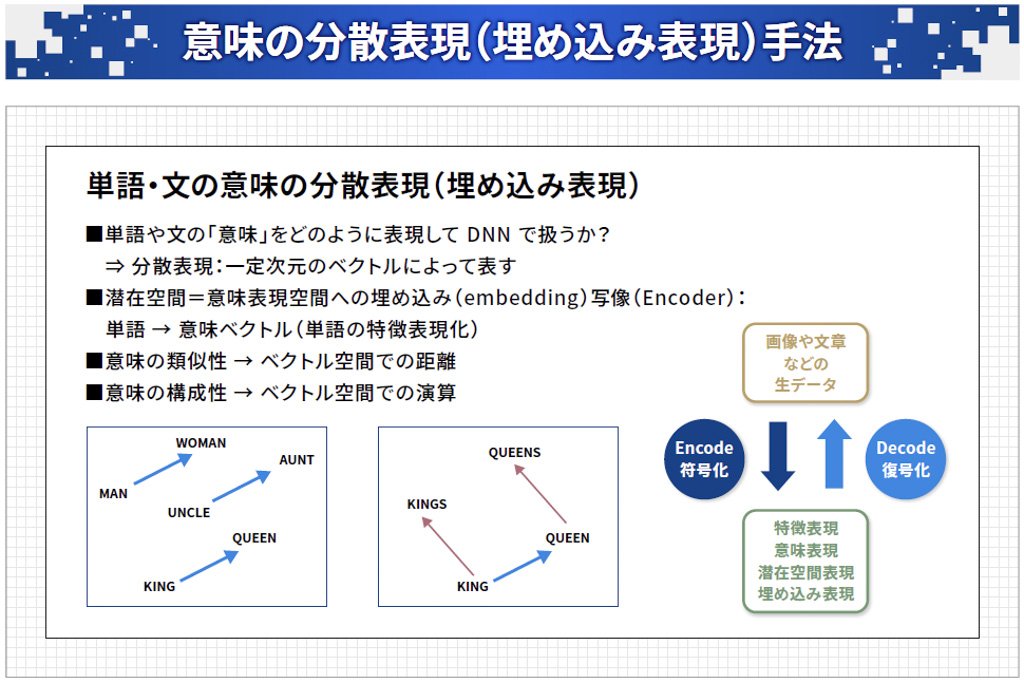
このため、文章や単語の意味をニューラルネットワークで扱うこと自体が難題でしたが、最近では「意味の分散表現(埋め込み表現)」という手法が開発されています。これは単語の意味を何百次元かのベクトルで表すもので、例えば「MAN」や「WOMAN」といった単語がベクトル空間の中のそれぞれ1つの点に対応します。
単語の意味の類似性は、ベクトル空間での点の距離に対応します。また、意味の構成はベクトル空間で加減算を行うことで計算できます。画像や文書などのデータを意味や特徴の表現に圧縮することを符号化(エンコーディング)、逆に圧縮された意味や特徴の表現を元に戻すことを復号化(デコーディング)と呼びます。(図表4)
Mikolov+: Linguistic Regularities in Continuous Space Word Representations, NAACL 2013 を基に一部改変
図表4:「意味の分散表現(埋め込み表現)」では、ベクトル間の距離や位置関係から単語の意味を表現できる
・Transformerによるブレイクスルー
「Transformer」は文章生成AIに不可欠な大規模言語モデル(Large language Model=LLM)を実現するきっかけとなった技術です。元々は翻訳用に考案されたもので、例えば英語の文章を入力すると、それに対応する日本語の文章を1単語ずつ生成することができます。図表5は、そのアーキテクチャで、入力した文章を意味を表すベクトルに変換するのが左側のエンコーダ部分、その意味を日本語の文章にするのが右側のデコーダ部分です。
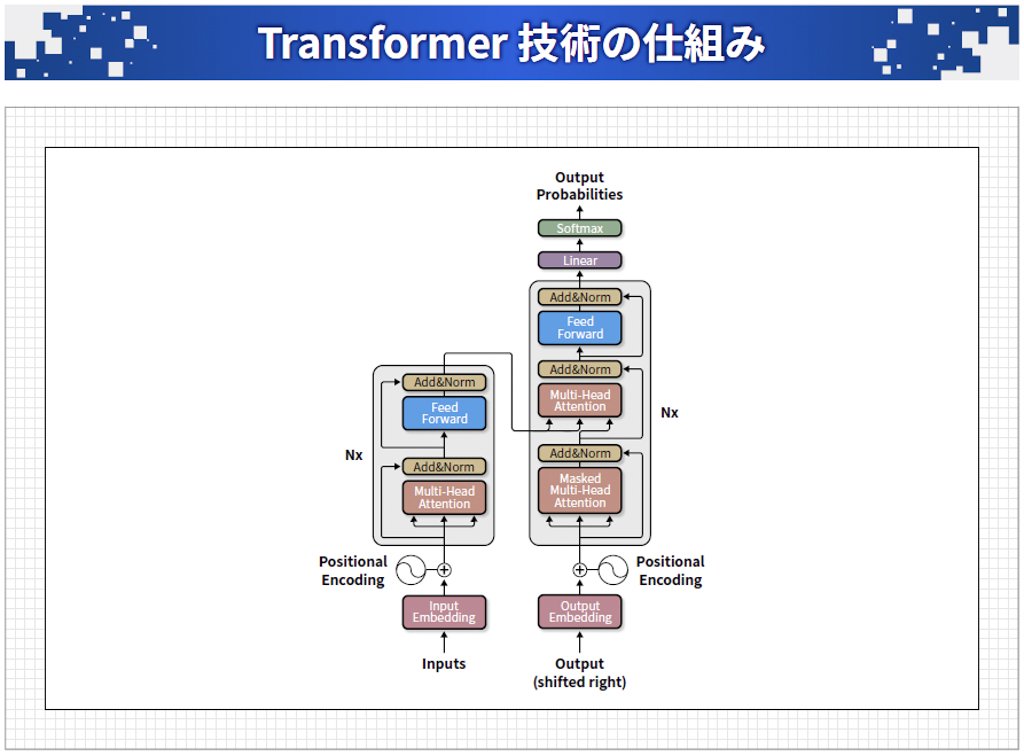
Vaswani+: Attention is all you need, arXiv: 1706.03762 を基に一部改変
図表5:英語の文章を入力すると、左側のエンコーダ部分で意味に変換し、右側のデコーダ部分で日本語の文章にする
Transformerの大きな特徴は、「アテンション(注意)」と呼ばれる機構です。画像の認識でよく使われるのは「畳み込みニューラルネットワーク」というもので、あるニューロンはその近くのニューロンだけから入力を受けます。一方、文章では長距離依存があり、かなり前の単語も見る必要があるため、全部のニューロンから入力を受けます。この時、現在の処理に必要な情報に「注意を向ける」のがアテンションで、それ自体も学習することができるため、文章を適切に処理することが可能になっています。(図表6)
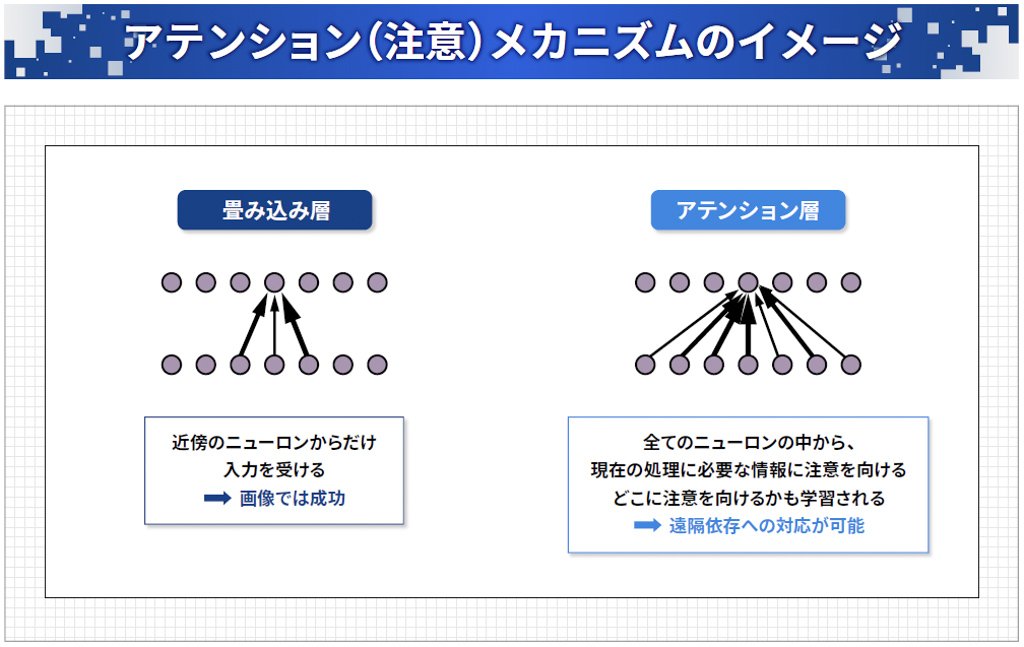
図表6:現在の処理に必要な情報に注意を向けて文章を適切に処理することが可能
図表7は、文章生成 AI の処理の様子で、左のエンコーダで英語の文章を意味表現に変換します。この意味表現と、今まで生成した「英国の首都は」までを使って次の単語である「ロンドン」を予測してサンプリングするという形で、1単語ずつ順番に文章を生成していきます。
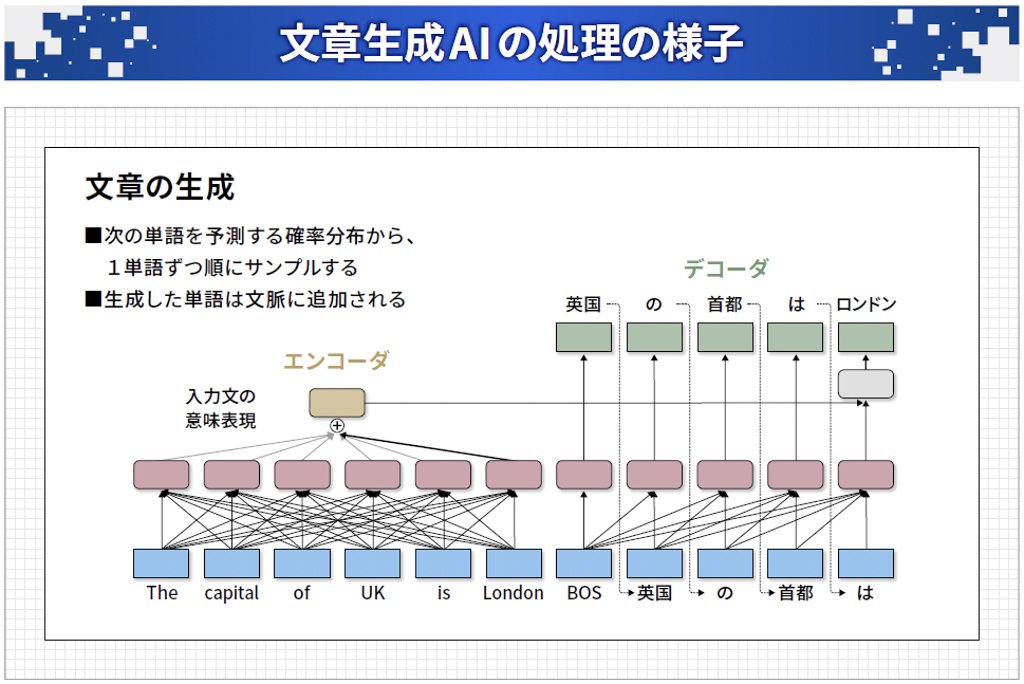
岡崎直観:ChatGPT の驚異と脅威、資料https://speakerdeck.com/chokkan/20230327_riken_llmを基に一部改変
図表7:1単語ずつ順番にサンプリングして文脈に追加していく
■GPT(Generative Pre-Trained Transformer)
文章生成 AI に使われる大規模言語モデルの中でひときわ有名なのが「GPT」です。GPTはTransformerが持つ意味表現から文章に変換するデコーダ部分だけを利用し、次の単語を予測するタスクを学習します。
最初にGPTが登場した2018年にはパラメータの数は約1.7億、2019年のGPT-2では15億でしたが、この後に「スケーリング則」と呼ばれる重要な発見がありました。パラメータとデータの数を増やすことで、予測精度が飛躍的に向上していくことが分かったのです。そして莫大な投資が行われた結果、2020年のGPT-3は1750億のパラメータを持つ巨大なものとなりました。現在ChatGPTで使われているGPT-4のパラメータ数は公開されていませんが、1兆個程度はあるといわれています。
生成AI(言語生成AI)の使い方
■ChatGPTの驚異と脅威
ChatGPTは2022年11月30日に公開されましたが、驚くほど流暢な自然言語文を生成し、文脈を考慮した受け答えをしてくれます。私は対話型ロボットの研究をしていたのですが、その立場から見ても想像を絶するもので、自分が生きている間にこんなものが現れるとは思わなかったというぐらいの衝撃でした。
また、文章だけではなくプログラムも生成できることから、非常に多くのユーザーが利用しています。技術の進歩も急速で、いろいろなサービスへの組み込みや機能追加が進んでいます。
■ChatGPTの使い方のコツ
ChatGPTは、入力文(プロンプト)を条件として、それに続く文章やプログラムを生成するため、プロンプトをできるだけ分かりやすく、かつ詳しく条件を指定するというのがポイントになります。
・タスクの指定
何をして欲しいかを明示します。
・役割の指定
「あなたは優秀な数学者です」のような役割を与えます。
・出力形式の指定
「箇条書きで」「表形式で」など、こういう形の回答が欲しいということを伝えます。
・生成時の注意事項
「ステップごとに出力してください」など。最近では「深呼吸してください」と入力すると性能が上がるという研究もあります。
・1度で答えてもらおうとせずに、質問を何回かに分けて対話的に進める
こうすると、前の答えを使って間違いを指摘し、より良い回答を求めることもできるようになります。
イメージとしては「とても物知りで真面目だが、受け身な部下」で、的確な指示さえすれば良い働きをしてくれるはずです。入力文をうまく書くための技術は「プロンプトエンジニアリング」と呼ばれていて、ノウハウになっているので、会社でChatGPTを利用する際にはプロンプトの共有やテンプレート化のほか、自動作成を試してみるのも良いでしょう。
■ChatGPTの課題と対応
ChatGPTの最大の課題は、「どうしてうまくいくのかはよく分かっていない」ということです。これは研究者であっても同様で、想像以上にうまくいっているというのが正直なところです。また、ChatGPTは文章の意味を理解しているわけではありません。一見そう見えるのですが、文章でしか学習していないので、いわば図書館の本だけで全てを学んだ人のような感じです。リンゴが赤いことは知っていますが、それは本に書いてあったというだけで、赤いリンゴを実際に見たことはないので人間のようには理解していないのです。
他にも以下のような課題がありますが、それぞれ解決に向けた対応が行われています。
・複雑な論理的推論や計算は苦手
例えば、膨大な桁数の掛け算をさせると一見それらしい答えは出すのですが、実際に計算してみると間違っていることがあります。これは人間と同様で、ChatGPTに計算機のような外部システムを利用させれば対処可能です。
・もっともらしい答えが間違っていることも多い
この問題に対しては、検索やファクトチェックとの組み合わせが行われています。ただ、インターネット上にAIが作ったコンテンツがあふれてくると、検索結果も間違っている可能性が増えていくので、最終的には正確性が保証されたよりどころとなるものを用意する必要があるかもしれません。
・学習や推論に大きなコストがかかる
膨大な電力消費は早急に対処すべき課題で、モデルをできるだけコンパクトにして、計算に必要なエネルギーを減らす研究が行われています。
・モデルが非公開
ライセンス独占されているという問題に対しては、オープンソースの学習モデルやデータの公開が始まり、利用が可能になってきています。
・学習データや生成物の著作権、プライバシーに関する懸念
著作権の扱い方や元データの権利者への還元方法などについて、世界的なルールの制定が検討されています。
・性能の評価が困難
性能評価の明確な基準の制定に向け、自然言語の処理や言葉の意味理解、推論・問題解決などに対する
ベンチマーク課題の整備が進められています。また、弁護士や医師の国家試験など、人間の試験を使った評価も行われているほか、最近では「Language Model Evaluation Harness」という、多くのベンチマーク課題を集めたものも公開されています
■ChatGPTの能力拡張
ChatGPTが苦手とする、あるいは単体では不可能なことへの解決策として、さまざまな能力拡張の方法が提案されています。
・ファインチューニング(転移学習、追加学習)
解きたい問題に合わせたデータを用意し、追加の学習を実施します。
・プロンプトによるチューニング
プロンプトにコマンドを書き込んだり、文中に例を示したりといった工夫をします。プロンプトがプログラミングのようなものになっているわけです。
・アライメント
人の嗜好や社会規範に沿った答えを出すように調整します。
・外部システムの利用・連携
例えば、プラグインを使うことで、LLMあるいはChatシステムから検索や予約サイトなどが外部システムを利用することができます。
・複数モデルの組み合わせ
ChatGPT同士を議論させることで、より良い結論を出させる研究も行われています。
その他にも、ChatGPTを強化するためのツールやプログラミング言語、ライブラリなどの環境も整備されてきています。
■活用事例
企業や組織では、業務の効率化がChatGPTの最も一般的な活用法だと思います。文書の作成・要約・翻訳、プログラムの作成・デバッグ、ヘルプデスクやFAQのほか、人材育成への活用として新入社員の指導役をChatGPTにやらせるということも行われています。さらにブレーンストーミングの支援や悩み相談、抜け漏れのチェックなどにも利用されています。
・全社的導入の例
例えば、パナソニック コネクト社では、2023年3月から全社員向けのAIアシスタントサービスを導入していて、6月にはその利用法を公開しています。質問・プログラミング・文書生成・翻訳などにおける利用の割合や、社員による評価なども公表しています。
ConnectAI活用実績と今後の戦略 記者説明会
https://connect.panasonic.com/jp-ja/newsroom/pr-20230628-01
・自治体での利用例
横須賀市では、2023年4月からChatGPTの全庁的な実証利用を開始し、6月には職員に対して実施したアンケート結果を公表しています。
ChatGPT活用実証結果報告
https://www.city.yokosuka.kanagawa.jp/0835/nagekomi/documents/yokosuka-chatgpt-2-houkoku.pdf
おわりに
生成AIは、最終的には情報の収集や学習を自律的に実行し、自分自身で賢くなる汎用AI(Artificial General Intelligence)に進化することが予想されています。ただ、大規模化による性能向上は限界に近いので、もう一段技術的なブレイクスルーが必要ではないかと考える人もいます。
一方で、Open AIは最近になって「スーパーアライメント」というプロジェクトを発表し、人間を超える知能を持つAIが完成した時に、それをどう管理するかを研究する動きを見せています。このように、AIの進化と並行して、その制御や研究開発の原則、セキュリティやプライバシー、知的財産権への配慮など、ルールや倫理面での整備も非常に重要になってくると考えられます。
この記事をシェアする