Technical Information
テキストマイニングによるテスト分析、リスクベースドテストへの応用

テキストマイニングは、文章を品詞レベルで分解し、情報·知識を得る技術です。
これを統計解析の手法と合わせることで、さらにデータの傾向や偏りをつかむことができます。この技術をテスト活動の上流工程で行うテスト分析やリスクベースドテストにどのように応用していくか、実践事例を交えながら解説していきます。
前半では、テキストマイニングの説明、テキストマイニングの活用例、テスト活動におけるテキストマイニングの親和性について、後半は、実際にプロジェクトの中でテキストマイニングを使ったテスト分析例、リスクベースドテストへの応用について紹介します。
※この記事は、『ベリサーブ アカデミック イニシアティブ 2019』の講演内容を基にした内容です。

株式会社ベリサーブ
西日本事業部
第3ビジネスユニット 堀川 透陽
1.テキストマイニング
テキストマイニングとは
テキストマイニングは、データマイニング手法の一つです。
データマイニングはデータからさまざまな統計解析手法やパターン認識、AIを用いた情報の取り出しなどを行う技術の総称です。テキストマイニングは、その中で、テキストデータを分析対象として、文章を品詞レベルで分解し、出現頻度や言葉のつながりから情報を取り出す技術です。
テキストマイニングのさまざまな解析手法について見ていきましょう。
まず、「形態素解析」と「構文解析」について説明します。「形態素解析」は、文章を品詞レベルで分解します。分解したものを次に「構文解析」して文章の構造から意味のつながりを解析します。
例文を見てみましょう。
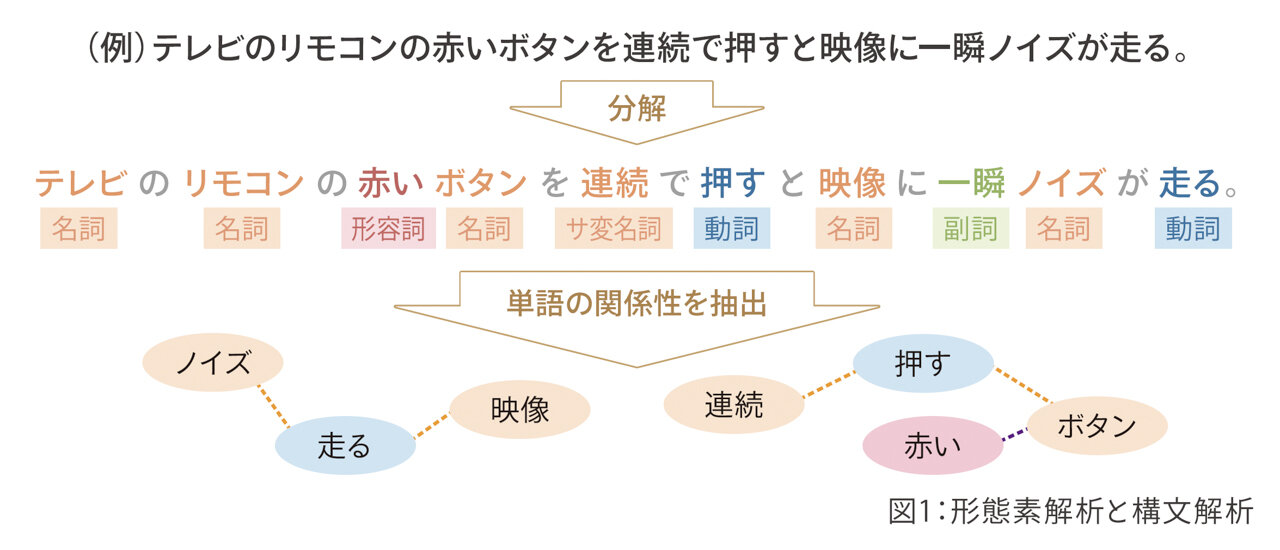
「テレビのリモコンの赤いボタンを連続で押すと映像に一瞬ノイズが走る。」
こちらを「形態素解析」で分解します。
「テレビ」「リモコン」「ボタン」は名詞です。他に「押す」「走る」といった動詞があります。副詞、形容詞といった品詞も分解されて出てきます。「構文解析」により、意味のつながりを可視化します(図1)。
テスト活動で分析を行うと、名詞は機能名であることが多く、動詞はその機能に対して、どうアクションするか、名詞、動詞を修飾する形容詞、副詞というのは、アクションの条件として現れます。テキストマイニングツールを使い、単語の関係性を抽出してこれをテストに活用します。
他の解析手法についても、見てみましょう。
テキストマイニングでよく見かけるデータ解析手法として、さらに3つ紹介します(後半で、事例として取り上げます)。
「共起ネットワーク」は、語同士のつながりの多さ、つながりの深さをネットワーク図にして可視化します。
「対応分析」は、相関関係を把握する散布図を用いて可視化して、データの特徴をつかみます。
「クラスタ分析」は、似た性質の単語をグルーピングします。
テキストマイニングの解析手法は、他にもたくさんあります。
簡単に可視化できるため、どれを使うか迷いますが、大事なことはテキストマイニングを使って何を得たいのか、解析の目的に合わせて手法を選択することです。とりあえず可視化する、ということでもよいですが、すぐに有益な情報が得られるわけではありません。あらかじめ仮説を立てて、目的に合ったデータ解析手法を用いるほうが、結果としては早く自分の仮説を立証できます。
テキストマイニングの活用例
「形態素解析」は大手ショッピングサイトでも見ることができます。
商品のカスタマーレビューを見ると、関連トピックのレビューを読む、という表示があって、関連語が並んでいます。単純な名詞だけでなく、動詞が混じっていることもあります。"テレビ"のレビューの場合、「初期不良」「電源を入れ」「リモコンの反応」などが表示されます。表示された語をクリックすると、その内容に関連したレビューが表示される仕組みです。
その他にも、テキストマイニングは、いろいろなジャンルで利用されています。
金融分野では、マーケット情報をテキストマイニングで解析して為替相場を予測するというサービスがあります。
特許調査では、他社の技術・出願動向を効率よく把握するツールとして使われています。非常に多くの件数を確認する必要があるので、効率的に早く特徴を把握したいということでしょう。
コールセンターでは、お客様への対応記録から顧客のニーズを引き出し、お客様対応の改善のために利用されています。
テキストマイニングを行う理由
なぜテスト活動(特にテスト設計)で、テキストマイニングを利用したほうがよいのでしょう。
一つは、分析の効率化です。先ほどの大手ショッピングサイトのカスタマーレビューの例では、100件、200件程度ですが、数年分、数千件以上のデータもすぐに一次解析できます。もう一つは、客観的、俯敵的にデータを見ることができるためです。
特に、ベテランの技術者になればなるほど、自分のパターンに固執して、そこから離れた思考が持てなくなることがあります。解析手法を用いて可視化することで、自分が思いつかないパターンが見えることがあります。プラスアルファの思考力を手に入れることができると言ってもいいでしょう。積極的にテキストマイニングを使っていただきたい理由はここにあります。
テストとテキストマイニングの親和性
テスト設計にテキストマイニング手法を用いることは本当に有効なのでしょうか?表lは、開発工程を含めて、テキストマイニングによる分析がどの工程に適しているのかを表にしたものです。各工程の成果となるドキュメントが、文章で記述されているものは、テキストマイニングの分析対象となります。

開発工程が進んでいくと、成果となるドキュメントの内容が文章から少し遠ざかっていきます。「基本設計」では、業務フロー図、機能一覧、ER図などが出てきて、記号化、モデル化されていきます。「詳細設計」で基本設計をやや文章化しますが、簡潔な文章になっていきます。 「ビジネス/ユーザ要求」、「要件定義」の分析がテキストマイニングと親和性の高いところ、つまり解析対象と言えます。
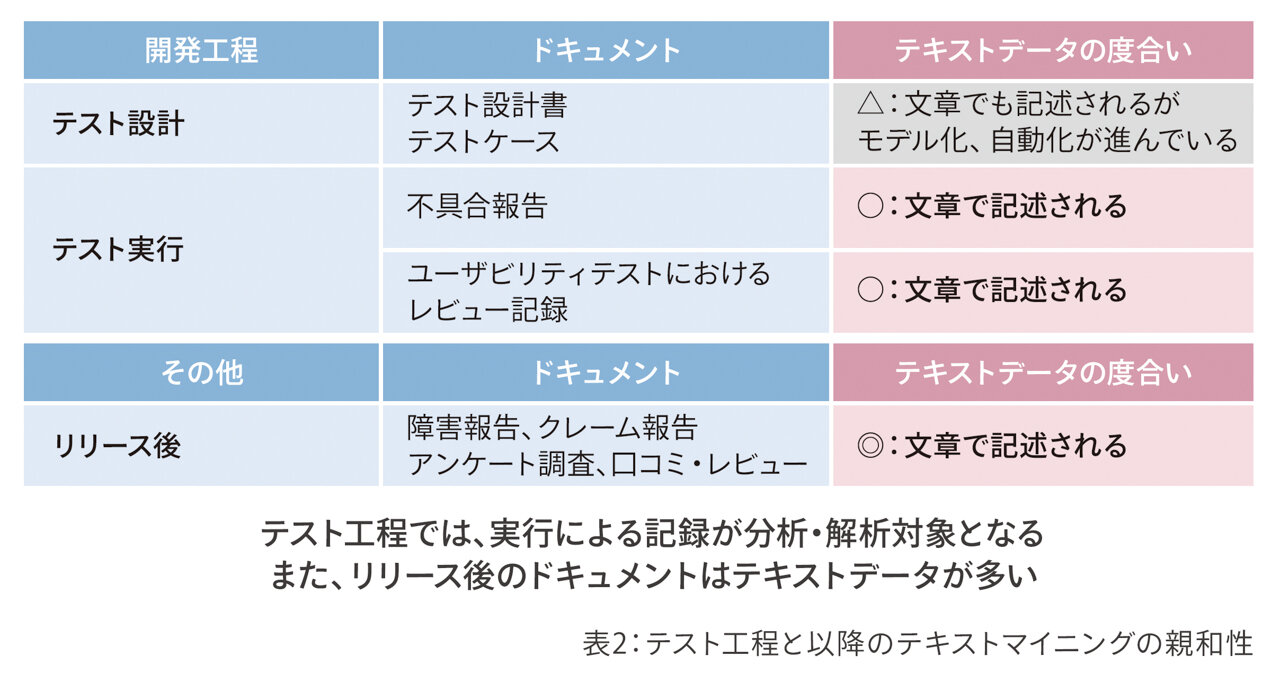
次にテスト工程のテキストマイニングとの親和性を見てみましょう(表2)。
「テスト設計」工程の成果物は、テスト設計書、テストケースです。
同工程の成果物を作るための分析なので、分析対象外とします。「テスト実行」では、成果物として不具合報告書が出てきます。文章で記述されるので、分析に適しています。不具合報告ではなく、ユーザビリティテストでも、いろんなご意見をいただくことができます。選択式のアンケートである場合もありますが、文章で記載されるところも多いので、分析可能としています。
そして、テスト工程が終わって、「リリース後」に出てくる障害報告、クレーム報告、顧客満足度調査、口コミレビューも文章で記述されています。ここが最もテキストマイニングが適している工程と考えます。一度リリースした後のユーザーの声です。これらのドキュメントを解析対象とすることで、市場不具合の少ない品質を目指したテスト設計ができる可能性が高いと考えていますので、二重丸にしました。
実際、この後に紹介する実践事例でも障害報告やクレーム報告といったリリース後に得られたお客様の声を中心にテストにフィードバックしたアプローチをしています。
2.テスト分析の実践事例
テスト分析~リスクベースドテストへの応用
テスト分析の実践事例を見ていきましょう。
取り上げる事例の開発・テスト状況を説明します。開発モデルは、ウォーターフォール型、新規開発ではない派生開発でした。テストチームは、結合テストから参画しています。テスト要員、テスト時間は少ない状況でした。お客様の悩みは、市場リリース後の製品にトラブルを多く抱えていることでした。また、市場不具合の情報は持っていましたが、開発にフィードバックできていませんでした。
市場不具合を減らすために、市場リリース後のトラブルに着目して分析を行い、テストチームが担当する結合テストに、まずフィードバックしようと考えました。
市場不具合に関して、すでに管理されていた情報がありました。「①コールセンターが受けたお客様からの間い合わせ内容」「②サポートエンジニアが現場で確認した事象」「③問題事象に対する開発側の考察」「④(考察を得て)お客様に行った対応内容」これらの情報が、すべてテキストデータという形で記録されていました。
テキストデータであるため、テキストマイニングによる解析が有効だと判断しました。さらにそのデータは数年分、開発にフィードバックされていないまま眠っていました。これだけの情報があれば、市場不具合をなくすことができると確信して、テキストマイニングを行いました。少ないテストリソースで、効率的なテストを行うために、市場不具合を解析して、問題の発生しやすい機能・条件を絞り込もうというテスト戦略です。市場不具合はどのような機能のつながりから出ているか、「共起ネットワーク」により可視化したものが図2です。
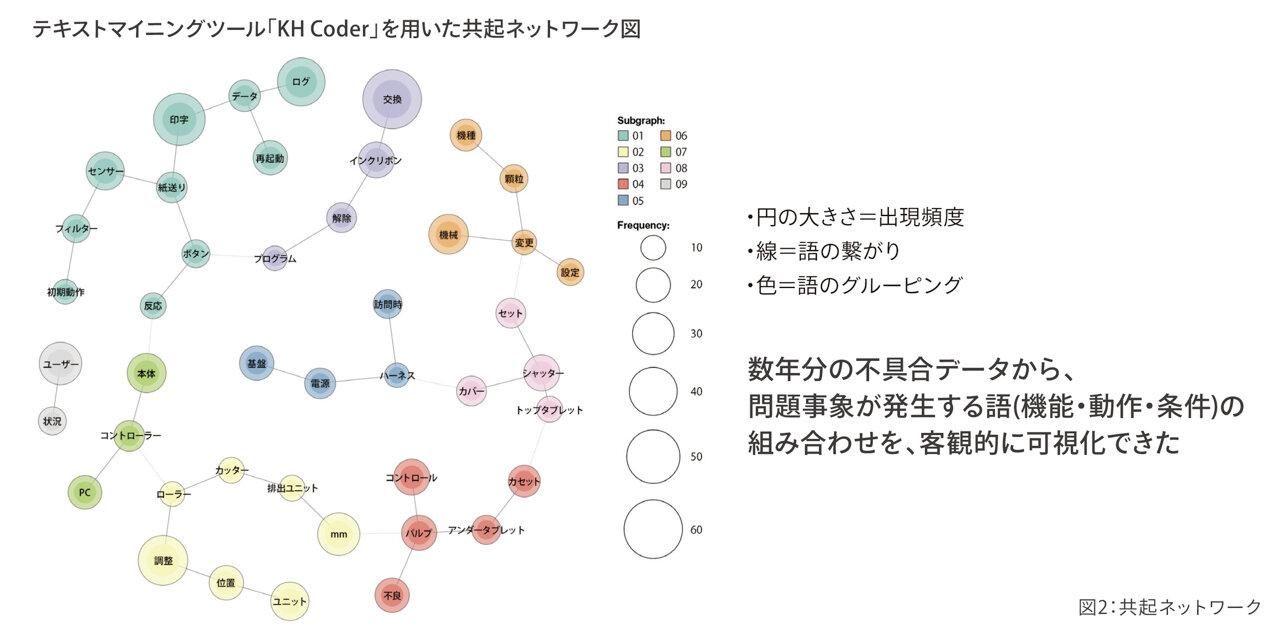
「共起ネットワーク」では、円の大きさは出現頻度・多さを示しています。
多く登場する語は、丸が大きいということになります。線は、語のつながりを示します。色が、語のグルーピングを示しています。色が異なり、線のつながっていないものは、何も関係がありません。配置にも意味はありません。
数年分の不具合データから問題事象が発生する語、機能・動作・条件の組み合わせをまず可視化しました。結合テストにフィードバックする分析については、特に「③問題事象に対する開発側の考察」をテキストマイニングしました。
開発工程に近い情報のほうが、テスト工程後半のシステムテストより、結合テストヘのフィードバックがしやすいと考えたためです。「①コールセンターが受けたお客様からの問い合わせ内容」の分析結果は、システムテスト工程のシナリオテストに用いました。
グルーピングした情報をそのまま使うこともできますが、さらにリスクを特定したいと考え着目したものが、中心性と呼ばれる概念です。中心性は、ネットワークの濃度、重要さを測る指標です。中心性が高い語、色の濃い部分をリスクの高いものとして使っていきます。中心性には、いくつかの概念があります(図3)。
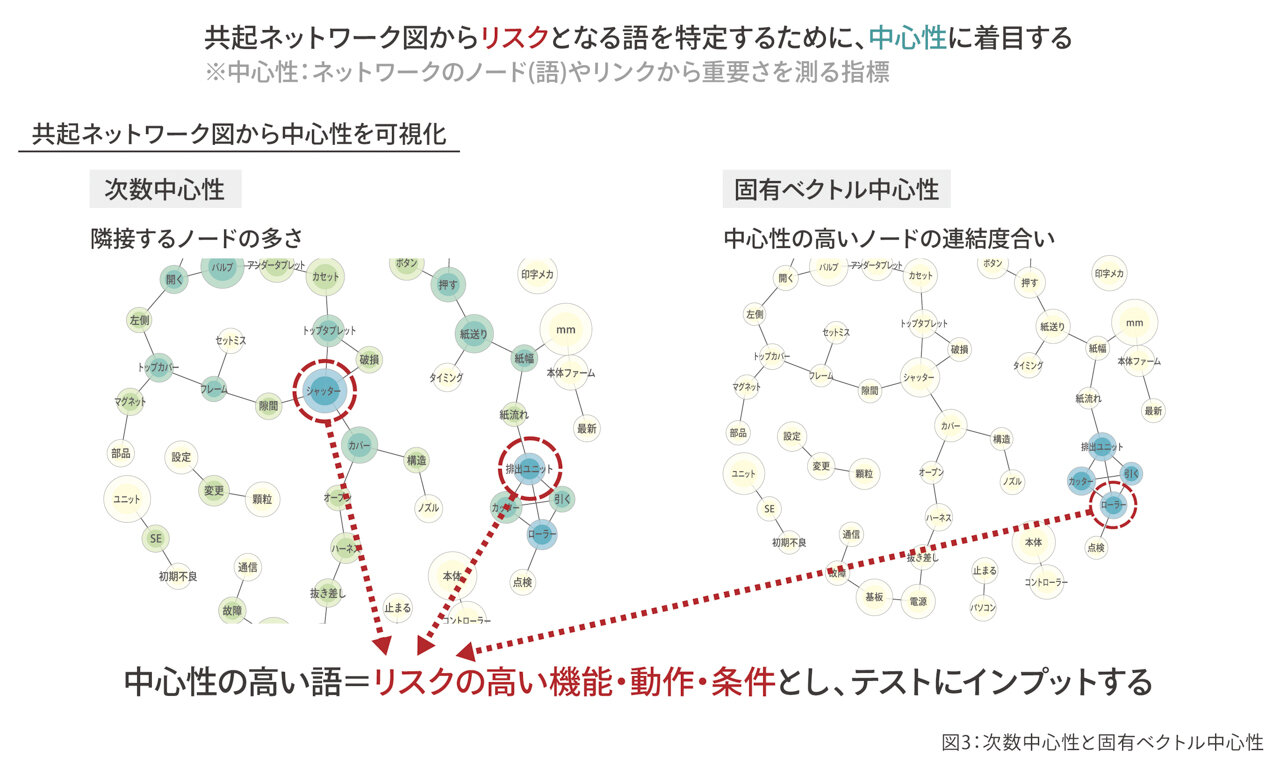
"次数"中心性は隣接するノードの多さを示しています。人間関係なら、友達の多さを示したものです。真ん中の色の濃い"シャッター"という語、右下で色の濃い"排出ユニット"という語は次数中心性が高いと判断できます。
もう一つ、"固有ベクトル"中心性です。中心性が高い濃度の連結度合いを示しています。
人間関係に例えると、友達が多い人とたくさん知り合っている人を示しています。自分に友達が多くなくても、友人に多くの友達がいる場合、中心性が高くなります。次数"中心性"、固有ベクトル"中心性"という同じ中心性という言葉であっても、異なる語が強調されて表示されます。そのため、一つの"中心性"ではなく、複数の"中心性"からリスクを捉えていこうと考えました。今回は、2つの"中心性"の高い語をリスクの高い機能として、テスト設計にインプットをしようと決めました(図4)。先ほど抽出したリスクが高いと判断した言莱を抜き出します(図の解析結果)。
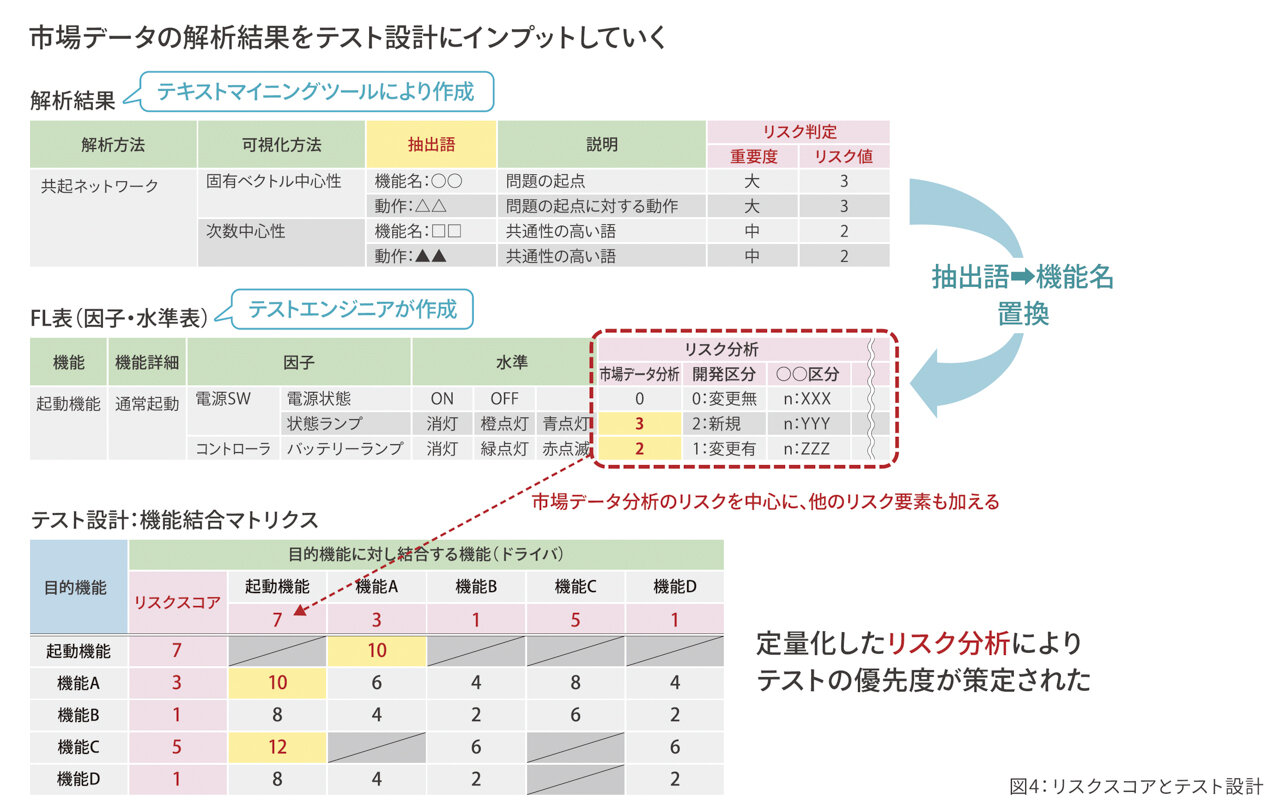
定量化するとわかりやすいので、リスクスコアとして、重要度をつけます。
解析結果の抽出語に関連する機能名を、テスト設計で用いるようなFL表(因子・水準表)と言われるテストエンジニアが作成する資料に反映させます。FL表からリスクスコアが出るので、こちらを基に機能結合マトリクスに展開します。
結合テスト以降を担当していて、目的機能に対する機能と機能間結合を見たかったので、リスクの高い機能同士を組み合わせて機能結合のリスクスコアを出しました。
この例では、機能結合マトリクスの黄色部分はスコアが高く、優先度が高いところです。
「起動機能」一「機能A」、「起動機能」一「機能C」が、テストの優先度が特に高い組み合わせとなります。このように優先度を明確にすることで、テストリソースをどこに当てはめるかを考えるときに、優先度が高いものからテストケースを選ぶことができます。
テキストマイニングのさらなる応用
テキストマイニングのさらなる応用として、「対応分析」「クラスタ分析」について、紹介します。
「対応分析」は、全体の特徴をつかみます。実際に、厚生労働省のサイトの『毎月勤労統計調査オンラインシステム更改及び運用・保守に係る業務ー式要件定義書」を使って、対応分析を行いました(図5)。
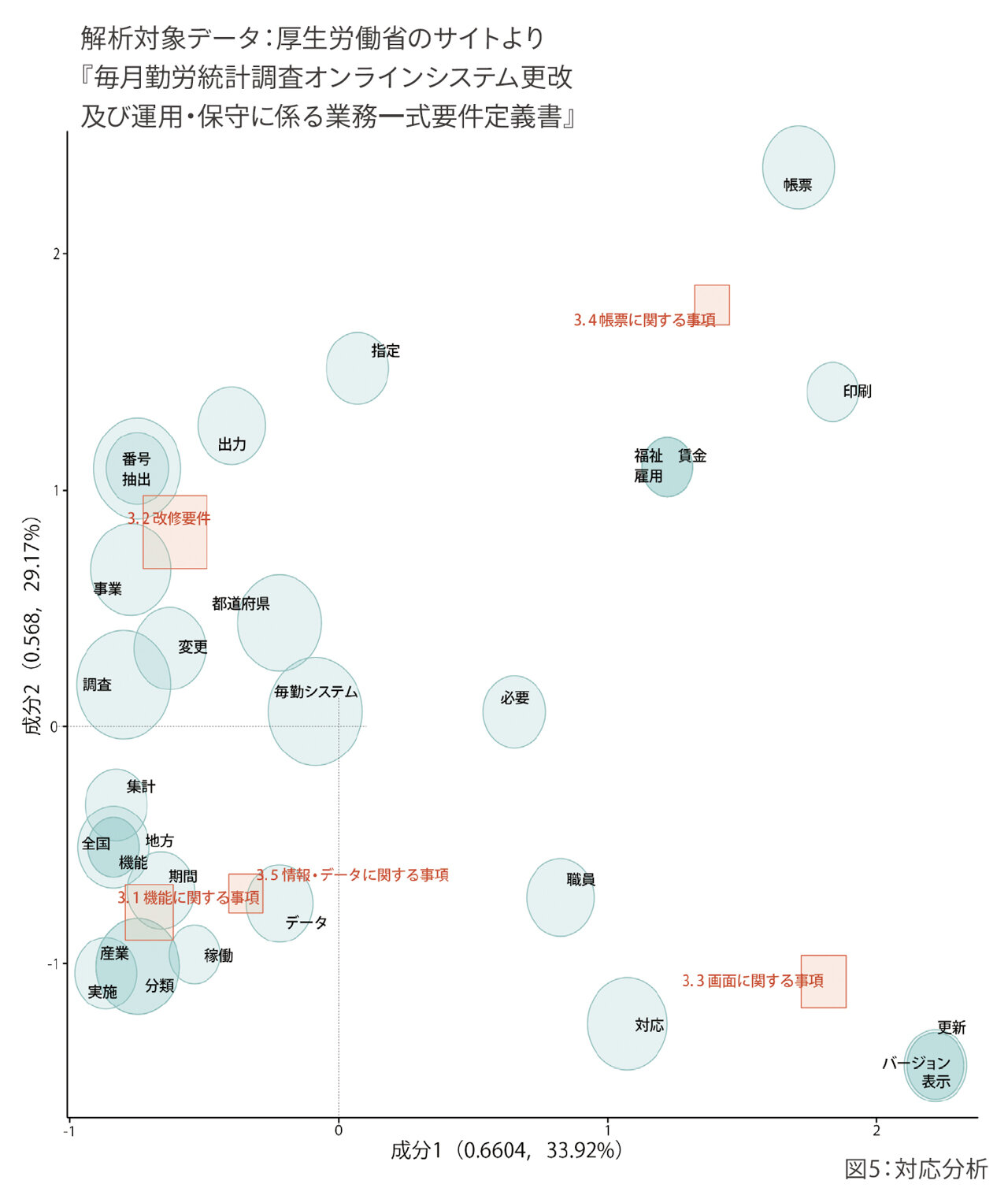
要件定義書全体をテキストマイニングで解析して、語同士の距離感と語とカテゴリ(章)の距離感を座標にした図となります。赤四角は、カテゴリ(章)です。カテゴリに近い言葉ほど、特徴的な言葉を示しています。カテゴリに属さない原点に近い語は、普遍的な非特徴的な言葉です。
こちらの例だと、"毎勤システム"という言葉がありますが、毎勤システムの要件定義書なので、当たり前の語で特徴がありません。
「印刷」という言葉は、「3.4帳票に関する事項」のカテゴリの中で、特徴的な語であることがわかります。
次に「クラスタ分析」を紹介します。「クラスタ分析」は、似た性質の単語をまとめます。仕様書を解析して、テストパターンを生成したいときに利用できます。こちらは仕様書全体から、出現パターンの似た語をグルーピングしています(図6)。
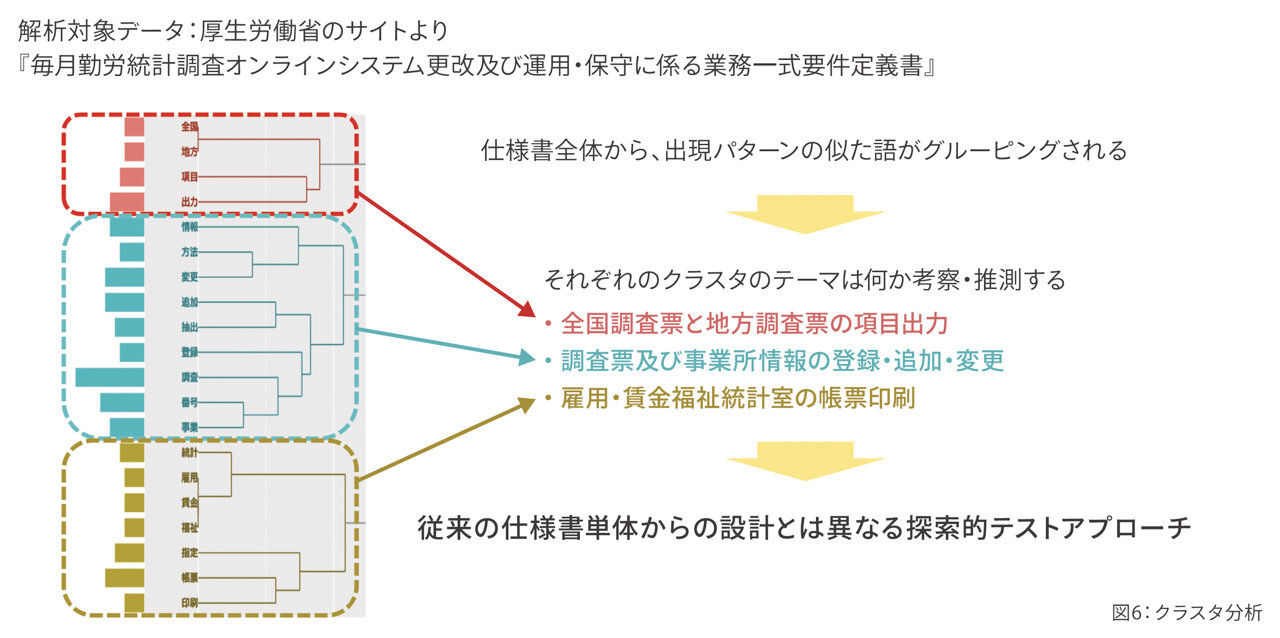
色がグルーピングを示しています。
トーナメント表のような形をしていますが、ここから、赤のグループは何をしているのかを推測すると、赤は全国調査票と地方調査票の項目に関するものをまとめられていることがわかります。このクラスタ分析の結果を基にテストケースにない探索的テストアプローチができるのではないかと考えています。
なぜ、探索的テストアプローチができるのでしょうか。
通常、テストを設計するときには、機能単位で考えて、テスト項目を抽出しているでしょう。A機能であればA機能の設計書に書いてあることから、テスト設計をします。「クラスタ分析」によるグルーピングにより、全体からパターンを作ることで、機能単位では考えられない、プラスアルファの視点が得られることがあります。
おわりに
テキストマイニングは、開発の上流工程、要求、要件分析と市場リリース後のデータに対して解析の親和性が高く、テスト分析に活用できます。本稿では、実践事例として、「共起ネットワーク」を使用して市場不具合を導く語のつながりを可視化しました。特に、中心性に着目して、リスクの高い機能·動作・条件を溝いて、リスクベースドテストにつなげる方法を紹介しました。さらに要求分析として、「対応分析」を用いたり、「クラスタ分析」により仕様書全体から探索的テストアプローチを考えたり、さらなる活用が期待できると考えています。
テキストマイニングはデータ分析の効率化、客観的な分析をして、これまでにない気付き、プラスアルファの思考力を得られるということをお伝えしてきました。本稿を読んで、ご興味が出てきた方は、ぜひ、テスト活動でテキストマイニングを活用してみてください。
この記事をシェアする