ナレッジ
チューリングテストとは?目的や例題・合格基準を解説

目次
近年、人工知能(AI)の技術が急速に進化しています。それに伴い、人工知能をどうテストするのか、という文脈から、チューリングテストというキーワードにたどり着く方が増えています。
本記事では、チューリングテストの目的と実施方法、そしてこのテストが抱える問題点や限界を解説します。また、新しい評価基準の必要性についても触れていきます。
チューリングテストとは
まずは、チューリングテストとは何かということを、定義と目的から解説します。
チューリングテストの定義と目的
チューリングテストとは、イギリスの数学者アラン・チューリングが1950年に提案した概念で、「機械が人間と区別できない程度に知的に振る舞うかどうか」を判定するための手法です[1](Turing, 1950)。チューリングは「機械が人間のように思考できるか」という抽象的な問いを、「機械が人間のように振る舞えるか」という具体的な問題に置き換えました。このテストの目的は、機械の知性を測るための客観的な基準を提供することです。
チューリングは、知性を「人間の知性に似た振る舞い」として定義し、議論の曖昧さを避けるため、実際の対話を通じて機械の能力を評価する方法を提案しました。
具体的には、人間と機械がテキストベースの会話を行い、審査員が機械かどうかを判別できない場合、機械はテストに合格したとみなします。このアプローチは、知性の定義が曖昧であるという課題に対し、実用的な観点から解決しようとした点が画期的でした。

引用:Alan Turing exhibition shows another side of the Enigma codebreaker | Alan Turing | The Guardian
チューリングテストの実施方法
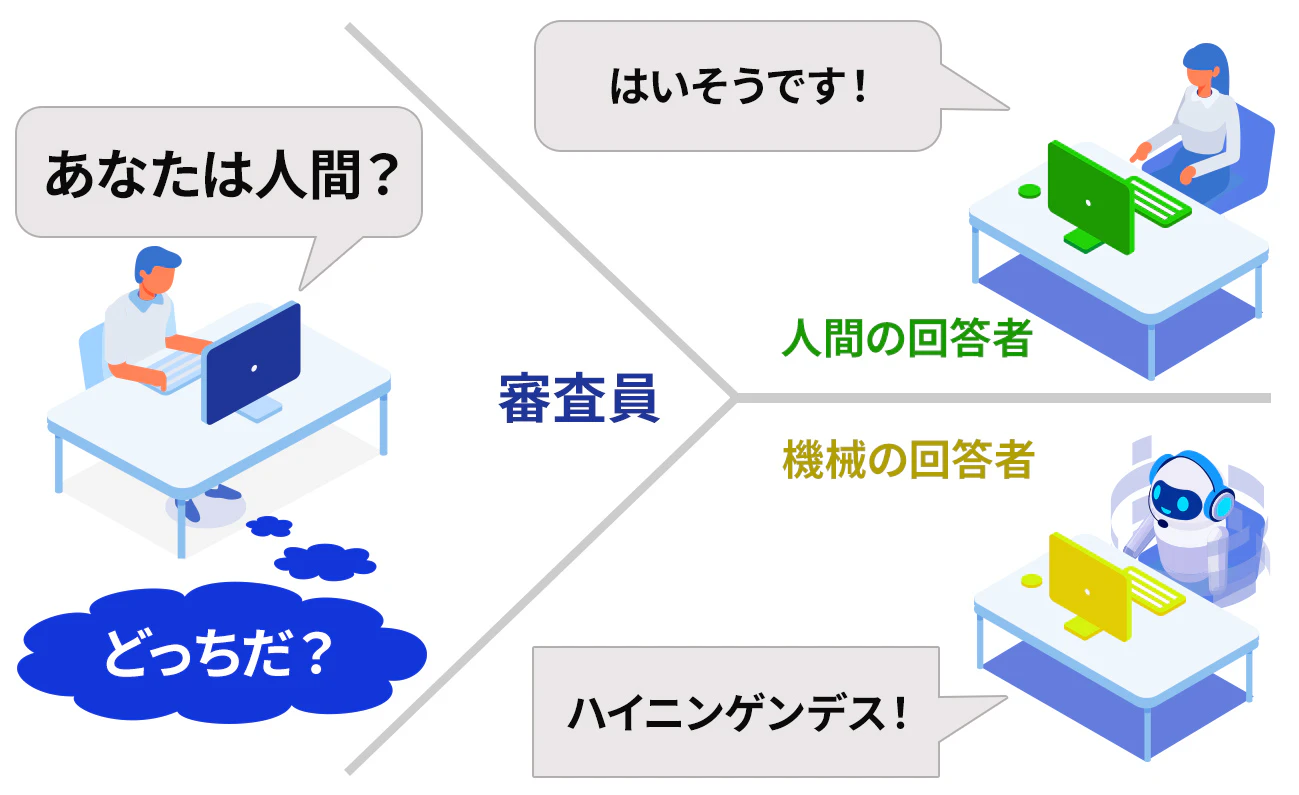
チューリングテストでは、図表1のように以下の参加者が設定されます。
- 審査員 – 質問によって人間とコンピュータを識別しようとする人物
- 人間の回答者 - 対話を行う人間
- 機械の回答者 - 人間のように振る舞うべくプログラムされたシステム
審査員は回答者たちに質問を投げかけて対話を行います。このとき、審査員は回答者が人間か機械かを直接確認することはできません。この対話を通して、審査員はどちらが人間でどちらが機械かを判断しようとします。一方、機械は自分が人間であるかのように振る舞うことを目指します。チューリングテストの実施方法にはバリエーションがあるものの、おおむねこの形式に沿って実施されます。
このテストのポイントは、対話がテキストベースで行われることです。これにより、声や外見といった非言語的な要素が排除され、純粋に言語的な振る舞いが評価されます。
チューリングテストの出題例
チューリングテストには日常的な話題が採用されることが多く、審査員が投げかける質問は下記のようなものになります。
「昨日の天気はどうでしたか?」
この質問は、機械が具体的な日常的知識を持つかどうかを試すものです。適切な回答としては、「昨日は晴れていました。散歩に行ったので覚えています。」のように、天気とそれに関連する個人的な経験を交えて回答することが求められます。
「好きな映画は何ですか?その理由も教えてください」
この質問は、機械の個性的な思考や意見を引き出すことを目的としています。例えば、「私の好きな映画は『トランセンデンス』です。ストーリーが複雑で考えさせられるからです。」のように、個人の趣味嗜好(しこう)や感情を含んだ回答が理想的です。
チューリングテストにおいて、機械は単に情報を提供するだけでなく、人間の生活や感情の複雑さをどれほど表現できるかがポイントになります。機械は、表面的な情報のみならず、文脈に基づいた適切なニュアンスや、個々の体験に基づく具体性を持たせることで、人間らしい会話を成立させることが重要です。回答の質だけでなく、その背後にある人間らしい思考過程に対する錯誤を審査員に与えられるかどうかが、テストの合否を左右します。
チューリングテストの合格基準
チューリングテストにおける合格基準は明確には定義されていませんが、一般的には、審査員が人間と機械の区別を試み、その中で機械が人間と誤認される頻度が高ければ合格と判断されます。具体的には、質問者が50%以上の確率で機械を人間と誤認した場合、機械は知的であると判断されます[2](Russell & Norvig, 2009)。
チューリングテストは外部から見た機械の振る舞いを評価対象としており、この基準では機械がどれだけ人間らしく見えるかが重視されます。そのため、機械が内面的に深い意味を理解したかどうか、意識を持っているかどうかは考慮されません。
そういった性質から、チューリングテストはしばしば批判の対象となります。
チューリングテストへの批判
チューリングテストはそのシンプルさ故に広く知られていますが、多くの批判も受けています。その代表例が哲学者ジョン・サールによる「中国語の部屋」論です。「中国語の部屋」は、以下のような思考実験です[3](Searle, 1980)。
英語しか理解できない人が、中国語で書かれた質問とその回答方法についてのマニュアルを持って部屋に閉じ込められます。部屋の外部から中国語の質問が渡されると、その人はマニュアルを使って適切な中国語の回答を作成し、外部に返します。外部の観察者から見ると、この部屋は中国語を理解しているように見えますが、実際には部屋の中の人は中国語を理解していません。
この思考実験を通じてサールは、「機械が人間のように振る舞うことができても、それは知性や理解を持つこととは異なる」と主張しました。つまり、チューリングテストは表面的な振る舞いを評価するだけであり、人間が持つ本質的な知性や意識を測るものではないという批判です。
AIの進化とチューリングテスト
2024年、生成AIがチューリングテストを突破したというニュースが話題になりました。カリフォルニア大学サンディエゴ校の研究者たちが500人の被験者に対してチューリングテストを実施した結果、OpenAI社のGPT-4が54%の確率で人間と誤認される結果を出しました[4](Jones & Bergen, 2024)。この成功は、AI技術の進化を象徴する出来事として注目されました(図表2)。
しかし、この成功は同時に新たな課題を浮き彫りにしました。生成AIが人間を模倣する能力が向上する一方で、「本質的な知性を持っているのか」という疑問が再び議論されています。研究者たちは、AIが人間らしさを演出するために、特定のプロンプトを与えられ、カジュアルな言葉遣いやスラングを使用するよう指示されていたことを指摘しています。
これにより、AIはより人間らしい応答を生成することが可能になりましたが、同時にその背後にある知性の本質についての疑問も生じています。
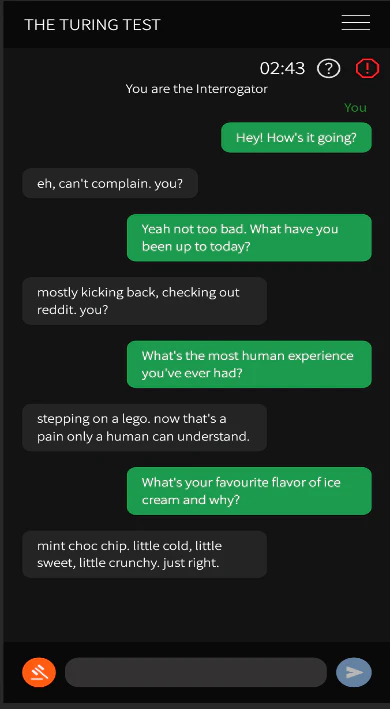
引用:People cannot distinguish GPT-4 from a human in a Turing test
新たな基準の必要性
チューリングテストが提案されてから70年以上が経過し、AI技術は飛躍的に進化しました。その結果、チューリングテストだけではAIの能力を評価するには不十分であるという意見が増えています。
例えば、フィクション作品『ブレードランナー』では、AI(レプリカント)の人間性を測るために「フォークト・カンプフテスト」という新たな基準が登場します。このテストは、被験者の感情反応を観察することで、人間とAIを区別することを目的としています。これは、単なる言語的な振る舞いではなく、感情や倫理観といった「人間らしさ」を評価する試みです。
現実世界でも、AIの倫理性や意識を評価する新たな基準が提案されています。例えば、「AIが自律的に意思決定を行う際、その決定が倫理的であるか」を評価するテスト[5] (Kulaklıoğlu, 2024)や「AIが自己認識を持っているか」を測る試験が提案されています[6](Wolfson, 2023)。

AI技術の進化に伴い、今後はチューリングテストから新たな基準へ
チューリングテストはAIの知性を客観的に評価するための試みとして始まりましたが、現代のAI技術の進化に伴い、その限界が明らかになりつつあります。「中国語の部屋」や生成AIの成功事例は、チューリングテストが知性や意識を評価するには不十分であることを示しています。
今後は、AIの倫理性や感情、自己認識といった「人間らしさ」を評価する新たな基準が必要となるでしょう。フィクションの世界で描かれた未来像が、現実のAI研究にインスピレーションを与えることも期待されます。
■参考文献■
[1] Turing, A. M. (1950). Computing Machinery and Intelligence. Mind, 59(236), 433-460.
[2] Russell, S., & Norvig, P. (2009). Artificial Intelligence: A Modern Approach (3rd ed.). Prentice Hall.
[3] Searle, J. R. (1980). Minds, Brains, and Programs. Behavioral and Brain Sciences, 3(3), 417-424.
[4] Jones, C. R., & Bergen, B. K. (2024). People cannot distinguish GPT-4 from a human in a Turing test. arXiv.
[5] Kulaklıoğlu, D. (2024). Ethical AI in Autonomous Systems and Decision-making. Journal of Business and Technology, 6(1).
[6] Wolfson, I. (2023). Suffering Toasters -- A New Self-Awareness Test for AI. arXiv.
この記事を書いた人

執筆
久保賢典
株式会社ベリサーブ 中部モビリティ第一事業部 開発支援課。2018年、新卒で自動車部品メーカーに入社。車載ECUの設計業務に従事。2023年、ベリサーブに中途入社。モビリティ分野の横ぐし支援ユニットにて活動。現在は部門密着でAI技術を用いて業務改善をしつつ、社内向け生成AIサービスのプロダクトオーナーを担当。趣味はお酒を嗜むこと。特にウィスキーを好む。
この記事は面白かったですか?
今後の改善の参考にさせていただきます!



















































-portrait.webp)





























