ナレッジ
教師データとは。データの作り方や学習データとの違いを解説

AIや機械学習について調べ始めると目にするのが「教師データ」という用語です。教師データはモデルの性能を左右する重要な要素であり、AIの開発や活用において欠かせない存在です。
本記事では、教師データの意味や役割、関連する用語との違い、作成の流れや注意点まで整理して解説します。
教師データとは
AIや機械学習を支える根幹の一つに「教師データ」があります。
AIにより現実世界のデータに対応した判断や予測を行えるようになるには、教師データの質と構成が大きな影響を与えます。まずは、「教師データ」の意味や他の用語との違いを以下にて整理します。
教師データの意味と役割
教師データとは、一つ一つに「正解」が付いているデータのことです。英語では labeled data や supervised data と呼ばれています。
例えば、画像認識のAIを作るときに「この画像は犬です」「これは猫です」といったラベルを付けた画像を大量に用意します。AIはこの用意されたデータから、どのような特徴が犬か、どのようであれば猫なのかを識別できるようになります。

このように、教師データはAIにとって学習の手本になります。正解を基に学ぶことで、AIは未知のデータにも対応できるようになるのです。
学習データとの違い
「学習データ」という言葉は、教師データより広い意味を持っています。AIが学習に使う全てのデータをまとめて学習データと呼び、その中に教師データ(ラベル付き)と非教師データ(ラベルなし)が含まれます。
つまり、教師データは学習データの一部です。「全ての教師データは学習データだが、全ての学習データが教師データとは限らない」と理解しておくと混乱しにくくなります。
訓練データや正解データとの違い
訓練データは、AIの内部の設定(パラメータ)を調整するために使うデータです。通常は教師データが使われますが、訓練データという言葉は「使い道」を表していて「正解ラベルの有無」には触れていません。
一方、正解データとは「このデータに対する正しい答え」を示します。教師データの中に含まれるラベルそのものを指すこともあれば、評価専用に使う答えだけを指すこともあります。言葉が似ている分、使い分けが紛らわしいので注意が必要です。
用語 | 内容 | 英語表記 |
|---|---|---|
学習データ | AIの学習に使う全データの総称 | learning data / dataset |
教師データ | 正解ラベル付きのデータ | labeled data / supervised data |
訓練データ | モデルのパラメータを調整するために使うデータ | training data |
正解データ | データに対して与えられる正しい答え | label / ground truth |
検証データ | モデルの過学習を防ぎ、ハイパーパラメータを調整するためのデータ | validation data |
テストデータ | 学習・検証に使っていない未知データで、モデル性能を評価するデータ | test data |
教師あり学習と教師なし学習について
AIモデルの学習方法は、大きく分けて「教師あり学習」と「教師なし学習」の二つに分類されます。違いは、正解ラベルの有無にあります。
どちらを使うかは、目的や手元のデータによって決まります。
教師あり学習の事例
教師あり学習は、ラベル付きのデータを基にモデルを訓練する方法です。入力に対する正しい出力が与えられているため、明確な目標に向かって学習できます。
例えば、「画像分類」は典型的な例です。猫や犬の画像に正解ラベルを付けて学習させると、AIは新しい画像を見たときに、どちらかを判別できるようになります。
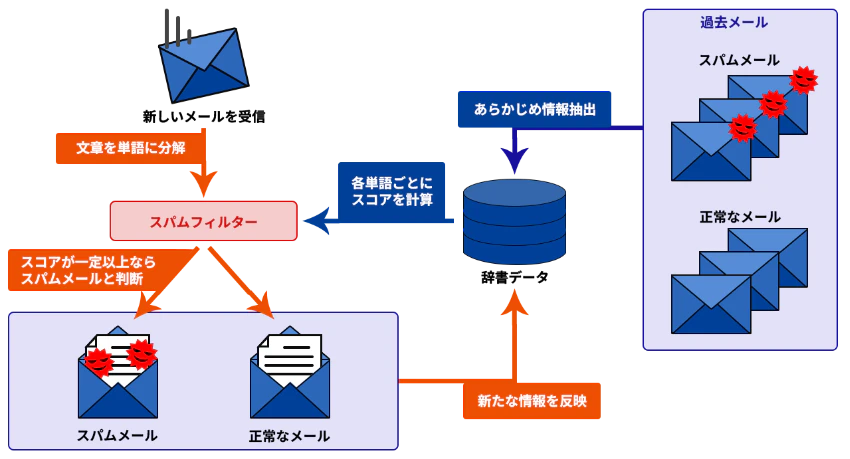
もう一つは「スパムメール判定」です。過去のメールに「スパム/通常」のラベルを付けて学習すれば、受信したメールが迷惑かどうかを自動で判断できるようになります。
このように、分類や数値予測のように「答えが決まっている問題」に適しています。
教師なし学習の事例
教師なし学習では、ラベルのないデータから傾向や構造を見つけ出します。正解がないため、AIが自らパターンを探る仕組みです。
よく使われるのが「顧客のクラスタ分け」です。購買履歴などを基に、購買傾向の似た顧客同士をグループ化することでマーケティング戦略に生かせます。
もう一つの例は「異常検知」です。工場のセンサーデータを常時学習させておくと、いつもと違うパターンを検出できるため、不具合の予兆に気付ける場合があります。
答えのない世界で、潜在的なルールや構造を発見したいときに向いています。
教師データの作り方とプロセス
教師データの作成には、幾つかのプロセスがあり、それぞれがモデルの性能に直結します。どの工程も丁寧に進めることが重要です。ここでは、一般的な流れに沿って各プロセスを解説します。
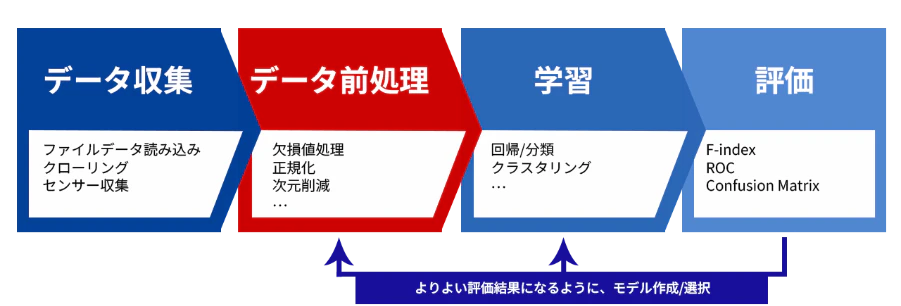
データの収集
目的に合ったデータを集めます。画像、テキスト、音声、センサーログなどAIが学習する対象に応じて素材はさまざまです。既存の公開データセットを利用する場合もあれば、自社システムやWebから独自に収集することもあります。
この段階では、データの多様性と量が後の精度に大きく影響します。
前処理とクレンジング
集めたデータはそのままでは使えないことが多く、欠損値の補完やノイズ除去などの処理が必要です。画像ならリサイズやトリミング、テキストなら文字化けの修正や記号の統一などを行います。
こうした前処理を通じて、AIが効率良く学習できる状態にデータを整えていきます。
アノテーション(ラベル付け)
教師データの核となるプロセスです。収集したデータに対し、人やツールを使って「正解となるラベル」を付与します。画像認識なら「この画像は車」、テキストなら「この文章はポジティブ」といった形でラベリングしていきます。
アノテーションには専用のツールを使うと効率的です。代表的なものは以下のとおりです。
ツール名 | 概要 |
|---|---|
Label Studio | 多言語・多形式対応のオープンソースツール |
CVAT | 画像・動画に強いラベル付けツール |
VoTT | Microsoftが開発した画像向けアノテーションツール |
作業ミスやラベルのばらつきを防ぐため、複数人でチェックする体制を設けることもあります。
品質チェックと検収
ラベルの正確性を確認するプロセスです。第三者によるダブルチェックを行い、判断のばらつきが多い項目は見直します。必要に応じてアノテーションのガイドラインを修正し、作業品質の安定化を図ります。
データの分割と保存
完成した教師データはそのまま使わず、役割に応じて分割します。通常は「訓練用」「検証用」「テスト用」に分け、それぞれの目的で使い分けます。
保存形式はCSVやJSONなどさまざまな形式があり、再利用やバージョン管理のしやすさも意識しておくと運用がスムーズになります。
Pythonを用いた教師データ作成の流れ
教師データの準備には膨大なデータ処理が必要となるため、自動化できる部分はプログラムを活用すると効率が大幅に向上します。特にPythonはデータ分析や機械学習分野で標準的に利用されており、教師データの作成にもよく使われています。
基本的な流れは次のとおりです。
- CSVや画像などの生データを読み込む
- 条件に応じてラベルを付与する
- 教師データとして保存する
例えば、テキストとスコアのデータがあり、スコアが0より大きければ「positive」、それ以外を「negative」と分類する場合、以下のように短いコードで処理できます。
import pandas as pd
# データの読み込み
df = pd.read_csv('input.csv')
# 条件に応じたラベル付け
df['label'] = df['score'].apply(lambda x: 'positive' if x > 0 else 'negative')
# 教師データとして保存
df[['text', 'label']].to_csv('teacher_data.csv', index=False)このようにPythonを用いると、手作業では煩雑な処理も自動で実行できて、ラベル付けの一貫性を保ちながら大量の教師データを短時間で作成できます。さらに、画像処理ライブラリ(OpenCVなど)やアノテーションツールのAPIと組み合わせれば、画像分類タスク用のデータ準備も容易になります。
教師データ作成時の注意点
教師データはAIの学習精度を大きく左右するため、作成過程での小さなミスや偏りがそのままモデルの性能低下につながることがあります。
ここでは、特に注意すべきポイントを解説します。
偏りのあるデータ収集
教師データに偏りがあると、AIは特定のケースにしか対応できなくなります。
例えば、顔認識モデルを開発する場合に特定の人種や年齢層ばかりを集めてしまうと、その他の属性に対する認識精度が著しく下がります。できるだけ多様な条件をカバーするサンプルを確保することが重要です。
アノテーションの品質不一致
ラベル付けの基準があいまいだと、同じデータに異なるラベルが付いてしまうことがあります。
これを避けるためには、作業者間で共通のルール(アノテーションガイドライン)を設け、複数人でクロスチェックする体制を整えることが効果的です。データの質のばらつきを放置すると、学習したモデルは安定した正解を導けなくなります。
プライバシーやセキュリティの軽視
実際のデータには、個人情報や機密情報が含まれることも少なくありません。画像や音声データには個人を特定できる要素が含まれるため、匿名化や加工を行い、法令に則った取り扱いを徹底する必要があります。
セキュリティ面を軽視したまま教師データが外部に流出すれば、思わぬリスクを招きかねないからです。
また、著作権や肖像権など利用するデータの現著作権者や権利保持者が持つ権利を侵害しないよう、データ利用前に確認し、必要に応じて許諾を得なければなりません。
教師データの重要性と活用の指針
教師データは、AI・機械学習の精度と信頼性を左右する重要な資産です。データ作成の工程には細心の注意が必要であり、アノテーション作業や品質管理にも工夫やツールの導入が求められます。教師あり学習と教師なし学習を使い分け、目的に合ったデータ作成と活用を進めていきましょう。
ここまで説明してきたように、AI導入を進める際には、教師データ作成のプロセスを正しく把握することが大切です。
そして多様な素材と高品質なラベリングによって、モデルの完成度を高めることがカギとなります。
ベリサーブではテストや品質保証の現場で培ってきたノウハウを生かし、AI時代のデータ品質向上にも取り組んでいきます。
■参考文献・引用元■
- 一般社団法人日本ディープラーニング協会
- 「The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards」|Sarah Holland, Ahmed Hosny, Sarah Newman, Joshua Joseph, Kasia Chmielinski
- CVAT公式サイト
- Label Studio公式サイト
- scikit-learn公式サイト
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!















































-portrait.webp)





























