ナレッジ
LLMとは何か。定義や仕組み、種類について分かりやすく解説

目次
ChatGPTの登場以降、「LLM(大規模言語モデル)」という言葉を耳にする機会が増えました。
とはいえ、その仕組みや従来のAIとの違いを正しく理解している人は多くありません。LLMは人間の言語を理解生成できる高度な学習を行うAIであり、生成AIの中心的な技術です。
本記事では、LLMの基本的な構造や種類、できること、活用を分かりやすく解説します。
LLM(大規模言語モデル)とは?
AI分野の発展を語る上で、いま中心的な役割を担っているのが「LLM(Large Language Model大規模言語モデル)」です。ChatGPTをはじめとする生成AIの土台にある技術であり、人間のように自然を理解し、図表1のように作り出せます。
ここでは、LLMの基本的な仕組みや種類、そして生成AIやGPTとの関係を分かりやすく解説していきます。
LLMの定義
LLMとは、膨大な文章データを学習し、言語の使い方や文脈のつながりを理解して新しい文章を作るAIのことです。
仕組みの中核を担うのは「トランスフォーマー」と呼ばれるニューラルネットワーク構造で、これが文脈を読み取りながら次に続く単語を予測します。この原理を「次トークン予測」といい、入力文(プロンプト)に対して確率的に最も自然な単語を一つずつ生成していく仕組みです。
LLMは言葉と言葉とのつながりを統計的に学習しており、パラメータ(AIが内部に持つ数値情報)が増えるほど、文脈の理解力や応答の精度が高まります。その結果、文章生成や翻訳、要約、プログラミングコードの作成など、幅広い自然言語処理に対応できる汎用性を持ちます。
LLMの種類
一口にLLMといっても、その目的や設計思想によって幾つかのタイプに分かれます。代表的な分類を整理すると、図表2のようになります。
分類軸 | 種類・例 | 特徴・用途 |
|---|---|---|
学習手法 | 基盤モデル(Foundation Model) | 大量のデータを基に事前学習された汎用モデル。多様なタスクの基礎となる。 |
指示追従モデル(Instruction-tuned) | 人間の指示やフィードバックを学習し、「〜して」「〜を説明して」といった指示に応じられる。 | |
構造 | SLM(Small Language Model) | 軽量で動作が速く、パソコンやスマホなどでも動かしやすい。 |
MoE(Mixture of Experts) | 複数の専門モデルを切り替えて処理する効率的な構造。 | |
用途 | 会話型、コード生成型、翻訳・要約特化型、エージェント型など | 特定の目的に合わせて設計されたモデル群。 |
提供形態 | クローズドモデル(例:GPT-5、Claude 4.5、Gemini 2.5 Pro) | 外部APIで利用できる高性能モデル。内部構造は非公開。 |
オープンモデル(例:Llama 4、Mistral、ELYZAなど) | モデルが公開されており、研究・開発用途にも利用される。 |
図表2:LLMの種類
このように、LLMには研究目的で使われるものから、一般ユーザー向けに提供される商用モデルまで幅広いバリエーションがあります。
最近では、画像や音声を同時に理解する「VLM(Vision-Language Model)」など、マルチモーダル対応モデルも増えています。
LLMと「生成AI」や「GPT」との違い
LLM、生成AI、GPTは似た言葉として使われますが、実はそれぞれが異なる概念を表しています。違いを次の図表3で整理しました。
用語 | 意味・範囲 | 主な例 | 関係性 |
|---|---|---|---|
生成AI(Generative AI) | テキスト・画像・音声・動画などを自動生成するAI技術の総称 | ChatGPT、Stable Diffusion、Sunoなど | 最も広い概念 |
LLM(大規模言語モデル) | 言語を理解・生成するモデル。生成AIの一部を構成する。 | GPTシリーズ、Claude、Geminiなど | 生成AIの中核技術 |
GPT | OpenAIが開発したLLMシリーズの名称 | GPT-3、GPT-4、GPT-4o、GPT-5など | LLMの代表例 |
ChatGPT | GPTを使った対話型サービス | chat.openai.com | GPTの応用サービス |
図表3:LLMに関連する用語の違い
つまり、「生成AI」という大きな枠の中に「LLM」があり、その中でも特定のシリーズとして「GPT」が存在します。そして、そのGPTを活用して作られたのが「ChatGPT」です。
なお、LLMはあらかじめ学習した知識を基に文章を生成するため、常に最新情報を持っているわけではありません。最新の社内データやニュースを扱う際は、外部の検索やデータベースと組み合わせて回答を補う「RAG(Retrieval-Augmented Generation)」という手法がよく用いられます。
LLM(大規模言語モデル)の仕組み
LLMが自然な文章を生成できるのは、単に大量のデータを覚えているからではありません。背後には「トランスフォーマー」と呼ばれる革新的な仕組みと、膨大なパラメータによる学習プロセスがあります。
ここでは、その二つのポイントを解説します。
トランスフォーマーと学習の仕組み
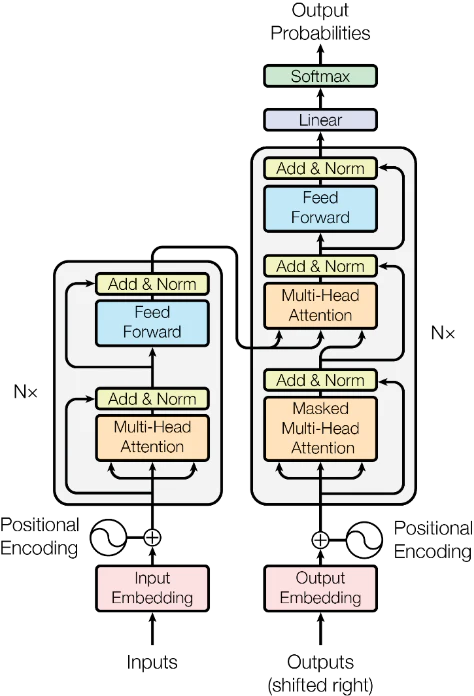
LLMの心臓部とも言えるのが「トランスフォーマー」です。これは文章内の単語同士の関係を並列に分析する仕組みで、長文でも文脈を保ったまま理解できます。
学習はまず、大量のテキストを使って「次に来る単語」を予測する事前学習を行います。その後、人の指示に従えるように調整したり(RLHF)、安全性を高める追加学習(Constitutional AI)を重ねたりして、実用的なモデルへと仕上げていきます。(図表4)
パラメータ数・トークンの概念について
LLMの性能に大きく関わるのが「パラメータ」と「トークン」です。パラメータはAIの知識の重みで、数十億〜数千億にも及びます。多いほど賢そうに見えますが、学習の質や構造も影響します。
一方トークンは、文章をAIが処理しやすい単位に分けたもの。文章の長さはトークン数で管理されており、上限を超えるとRAG(検索拡張生成)で補う必要があります。
LLM(大規模言語モデル)でできること
LLMは、単に文章を作るだけの技術ではありません。さまざまな業務に応用できる柔軟性を持ち、企業や個人の作業を大きく効率化する力を秘めています。
ここでは、代表的な三つの活用分野を紹介します。
文章生成・要約・翻訳
もっとも身近な使い方が、文章の自動生成や要約、翻訳といった言語処理です。
例えば、商品紹介文やFAQ、ビジネスメールなどを自然な文体で自動作成できます。また、会議の議事録や研究論文などの長文を要点だけにまとめることも得意です。
翻訳についても、英語はもちろん他の言語にも対応でき、ビジネス用途で使える精度を持っています。さらに「敬語で」「カジュアルに」「固有名詞はカタカナに統一」など、文体や用語の統一ルールも指示できます。こうした柔軟性により、ブランドガイドラインや社内表記ルールに沿ったテキスト生成にも対応できます。
コード生成や検索支援
LLMはプログラミングの領域でも活躍しています。要件や指示を書くだけで、対応するコードのひな形や補助説明を出力できます。
例えば以下ができます。
- 疑似コードの生成
- テストコードの作成
- エラー原因の特定
- 静的解析の支援
コードについて説明させたり、未経験者の学習支援に使われたりしています。
また、検索支援では「RAG(検索拡張生成)」という手法が使われることが多く、社内のマニュアルやナレッジベースから必要な情報を探し出し、根拠付きで回答を生成できます。これにより、社内問い合わせ対応やトラブルシューティングの初動が大幅に早くなります。
画像・音声と組み合わせたマルチモーダル対応
最近のLLMは、テキストだけでなく画像や音声など、図表5のように複数の情報を同時に扱えるマルチモーダル対応が進んでいます。
例えば、スクリーンショットやPDFファイルの図表を読み取り要約したり、UIの説明を自動生成することができます。
音声データでは、会議録音から議事要約の作成や、インタビューの文字起こしにも使われています。
さらに、業務フロー図や設計図を読み込んで、手順説明を生成するといった応用もあります。これは「VLM(Vision-Language Model)」という画像と文章を組み合わせた技術で、今後の業務効率化を支える重要な方向性となっています。
LLM(大規模言語モデル)のメリット・デメリット(課題)
LLMは幅広い用途に対応できる柔軟性があり、短期間で試作品(プロトタイプ)を作れる点や、APIやオープンモデルを選べる点が強みです。業務の効率化や自動化を進める上で有用な技術と言えます。
一方で、事実と異なる情報をもっともらしく生成してしまう「幻覚(ハルシネーション)」や、偏見のある出力、入力からの情報流出といったリスクもあります。対策としては、外部データと組み合わせて根拠を示す「RAG」や、安全性を確保する設定・検証が重要です。
代表的なLLM(大規模言語モデル)のモデル一覧
2024年以降、LLMは驚くほど多様化し、用途や規模に応じて最適なモデルを選ぶ時代に入っています。
ここでは、現在広く使われている代表的なモデルを、図表6にて公開形態・特徴・日本語対応の観点から分かりやすく比較します。
モデル系統 | 最新バージョン | 公開形態 | マルチモーダル対応 | 日本語対応の目安 |
|---|---|---|---|---|
OpenAI GPT | GPT-5 | クローズド(API提供) | GPT-4o以降は音声・画像・動画に対応 | 高い(実務導入例も多数) |
Anthropic Claude | Claude Sonnet 4.5 | クローズド(API提供) | Claude 3以降は画像入力に対応 | 高い(長文処理に強み) |
Google Gemini | Gemini 2.5 Pro | クローズド(API提供) | テキスト・画像・音声・コード対応 | 高い(マルチ用途に強い) |
Meta Llama | Llama 4 | オープン(商用利用可) | Llama 3.1以降で一部派生が画像対応 | 高い(日本語学習も強化) |
Mistral / Mixtral系 | Mixtral 8x7Bなど | オープン(軽量高速) | テキスト特化(画像未対応) | 中〜高(高速処理に強み) |
ELYZA 日本語LLM | ELYZA-Shortcut-1.0-Qwen-32B | オープン(日本語特化) | テキスト特化 | 日本語に最適化(実務用途中心) |
※2025年10月時点
図表6:代表的なLLMによるモデル
これらのモデルは、性能(推論速度・精度)、柔軟性(APIやローカル対応)、対応言語やモダリティなどの観点から選ばれることが多く、業務利用においては「何を重視するか」によって選定基準が変わります。
LLM(大規模言語モデル)の活用事例
LLMは、社内業務の効率化からプロダクト開発まで幅広い場面で応用されています。
例えば、ナレッジ検索では、RAG(検索拡張生成)を使って社内規程や設計書から根拠付きの回答を自動生成し、問い合わせ対応にかかる時間を短縮できます。開発支援の現場では、仕様書からテスト観点を抽出してテストケース案を自動で作成し、コードの静的解析と組み合わせることでレビュー工数を抑える取り組みも進んでいます。
マーケティング分野では、顧客ごとのセグメントに合わせたメール文やLPの文案を複数パターン作成し、A/Bテストの下書きに活用する使い方が定着しつつあります。文体や表記ルールへの適合チェックまで自動化することで、制作フロー全体をスリムにできます。また、グローバル展開を見据えた技術資料の翻訳や用語統一も、LLMによって一貫処理がしやすくなっています。
実際の導入例としては、メルカリがLLMを用いて出品商品のカテゴリ分類精度を大幅に改善しています。短い商品名や曖昧な説明文にも対応できる柔軟な判定が可能になり、ユーザー体験の向上とレビュー作業の自動化につながっています。1日数百万件に上る出品にも対応可能なスケーラビリティーを備えており、LLMOps(モデル運用と評価体制)を組み合わせた実践的な活用事例と言えるでしょう。
参照:LLMを活用した大規模商品カテゴリ分類への取り組み|mercari engineering
実務でLLM(大規模言語モデル)を活用するための最小構成ポイント
業務にLLMを取り入れるには、大規模なインフラや高性能GPUが必要だと思われがちですが、小規模な環境や限定された用途でも運用できる方法があります。
ここでは、ローカル実行・検索連携(RAG)・追加学習という三つのポイントに絞って解説します。
ローカルでLLMを動かすには
機密性が高いデータを扱う場面では、インターネットを経由せずローカルでLLMを実行する方法が選ばれることがあります。
例えば「Ollama」や「llama.cpp」といった軽量実行環境では、量子化済みのGGUF形式モデルを使うことで、GPUやメモリを8GB前後搭載したノートPCでも推論ができます。以下はその一例です。
# Ollamaを使ったLlama 3の起動
ollama pull llama3
ollama run llama3
# llama.cppで量子化済みモデルを実行
./main -m models/llama-3-8b-q4_0.gguf -p "日本語で自己紹介してください。" 根拠付きの回答を返すRAG
LLMが学習していない最新情報や社内特有の知識を取り込むには、「RAG(検索拡張生成)」が有効です。あらかじめ文書をベクトル化しておき、質問に対して類似する文書を検索・挿入することで、事実に即した応答が可能になります。
FAQ対応や技術文書検索など、情報の鮮度と正確性が求められるシーンで重宝される方法です。
関連記事:AI技術「RAG」とは?仕組みや生成AIとの関係など分かりやすく解説
どうしても足りない部分は追加学習
RAGでも対応しきれない場合は、追加学習やファインチューニングによって特定タスクへの適応度を高めます。代表的な手法であるLoRAは、モデル全体を再学習することなく少量のパラメータだけを更新する仕組みで、学習コストを抑えながら精度を補うことができます。
LLM(大規模言語モデル)を安全に活用するための次の一歩
LLMは、トランスフォーマー構造を基に言語パターンを学ぶ生成モデルで、文章生成や検索支援、マルチモーダル対応など多様な用途に広がっています。一方で、幻覚や情報漏えいのリスク、運用コストなど課題も多く、慎重な導入が求められます。
まず、根拠を示せるRAGの導入や、小規模なローカル実行・API活用から始めるのが実務的でしょう。
■参考文献・出典■
- Vaswani, A. et al., “Attention Is All You Need” NeurIPS 2017.
- Lewis, P. et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP,” NeurIPS 2020.
- Ouyang, L. et al., “Training language models to follow instructions with human feedback,” 2022.
- Anthropic, “Constitutional AI Harmlessness from AI Feedback,”
- Kudo, T. , Richardson, J., “SentencePiece: A simple and language independent subword tokenizer,” 2018.
- Hu, E. J. et al., “LoRA: Low-Rank Adaptation of Large Language Models,” 2021.
- Fedus, W. , Zoph, B., Shazeer, N., “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,” 2021.
- Zheng, L. et al., “Judging LLM-as-a-judge with MT-Bench and Chatbot Arena,” LMSYS, 2023.
- LMSYS, “Chatbot Arena Leaderboard.”
- Hugging Face, “Open LLM Leaderboard.”
- NIST, “AI Risk Management Framework 1.0,” 2023.
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!















































-portrait.webp)





























