ナレッジ
生成AIの仕組みとは?図解を交えて分かりやすく解説

目次
生成AIという言葉を耳にする機会が増えましたが、具体的にどのような仕組みで動いているのかは案外分かりにくいものです。文章や画像を生み出すプロセスには、幾つか押さえておきたい基礎があります。
この記事では、生成AIの内部で起きている処理や関連する用語を整理しながら、全体像をつかめるように解説していきます。
生成AIの仕組みに関わる各用語の説明
生成AIの流れを理解するには、モデル内部で扱われる幾つかの用語を押さえておくと全体像がつかみやすくなります。
ここでは、仕組みの基盤となる四つの概念を整理し(図表1)、その後に具体的な内容を順に説明していきます。
用語 | 役割の概要 |
|---|---|
LLM | 言語パターンを学習し、文章を組み立てる中心的なモデル |
学習データ | モデルが知識や規則を得るための材料 |
ベクトル表現 | 言語や画像を数値に変換し、計算可能な形にする仕組み |
確率的推論 | 候補の中から次の語や表現を選ぶプロセス |
図表1:生成AIの基本概念と役割
LLM
LLM(Large Language Model)は、大量の文章を読み込んでパターンを学び、人が書くような文章を組み立てるモデルです。文脈をざっくり暗記しているというより、膨大な例から「次に続きそうな語の傾向」を統計的に捉えているイメージに近いです。
文章を理解し、質問に答えたり要約したりできるのは、この学習で身に付けた文脈の扱い方が深く関わっています。
関連記事:LLMと生成AIの違いとは?それぞれの仕組みやできることを解説
学習データ
LLMが扱う表現の幅は、学習に使われたデータの種類に影響を受けます。ウェブ上の文章、書籍、会話の記録、コード、画像と説明文の組み合わせなど、多様なデータから規則性を見つけていきます。
学習前には、重複を削ったり、ノイズを取り除いたりといった前処理を行い、モデルが扱いやすい状態に整えます。扱うデータのトピックに関する領域が幅広いほど、多様な話題に対応しやすくなります。
ベクトル表現
文章や画像をそのままの形で計算することはできないため、内容を数値に置き換える工程が必要です。この数値の並びをベクトル表現と呼びます。
文章はまず細かな単位に分割され、各単位がベクトルへ変換されます。意味が近い語ほど近い位置に並ぶように設計されているため、関連する情報を引き寄せたり、画像と文章を結び付けたりする基盤としても働きます。
確率的推論
生成AIは、候補の中から「次に来る可能性が高い語」を選びながら文章を作ります。この選び方が確率的推論です。
設定によって、候補を幅広く探索することも、確度の高い語に絞ることもできます。創造性が欲しい場面では選択肢を広げ、安定した文章を作りたい場面では絞り込む、といった調整が可能です。
画像や音声の生成でも、確率に基づき段階的に形作っていく考え方が共通しています
生成AIの仕組みを分かりやすく図解
生成AIの内部では、入力を理解し、数値の世界に変換し、確率に基づいて出力を組み立てるという一連の処理が段階的に進みます。テキストでも画像でも、基本的な流れは共通しています。まずは構造を大づかみにできるよう、全体像を図表2で示します。
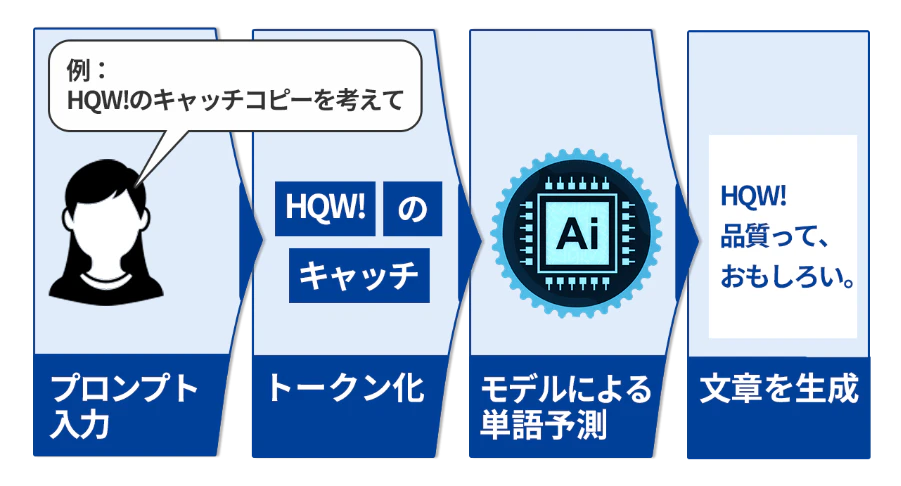
まず、入力された文章や画像は、そのままでは扱えないため、前処理で形式を整えます。文章であれば単位ごとに区切るトークン化、画像であればサイズの整形や特徴抽出などが行われます。
次に、モデルが計算できる形にするため、内容をベクトル表現(数値の並び)へ変換します。この変換によって、意味の近さや関連性を計算で扱えるようになります。
その後、変換された情報がモデルに渡され、確率に基づく推論が行われます。ここで、次の語の候補や、どの描写が条件に合うかなどが段階的に判断されます。
最後に、推論で得られた結果が人に読める形や見える形に戻され、文章・画像・音声などの形式で出力されます。
生成AIのテキスト生成の仕組み
テキスト生成は、入力された文章を理解し、続きとして自然な語句を選びながら文を組み立てていく仕組みです。内部では一定の順序で処理が行われており、その流れを追うとモデルの動きをイメージしやすくなります。
ここでは、生成の流れを段階ごとに整理します。
1)文章を細かな単位に分割する
モデルは文章をそのまま扱えないため、まずは内容を小さな単位に区切ります。これがトークン化です。単語全体ではなく、語の一部を単位にする方式も用いられています。扱う単位を細かくすることで、未知の語でも近い形を推定しやすくなります。その代わり、トークンが小さいと計算コストは増大するためバランスが重要になります。
2)数値へ変換する
区切られたトークンは、意味の特徴を反映したベクトルへ変換されます。数値に変換されることで、語同士の距離や関連性を計算の対象として扱えるようになり、文脈のつながりを捉えやすくなります。
3)文脈を踏まえて次の候補を考える
ベクトル化された情報はモデルに入力され、文脈から「次に続きやすい語」が確率として計算されます。過去のどの部分をどれくらい参照するかを判断する仕組みが働き、文全体の流れを踏まえた候補が提示されます。
4)設定に応じた選択方法で語を決める
候補の中からどの語を採用するかは、設定によって調整できます。選択肢を広げて多様な文章を目指すことも、確度の高い語を選んで落ち着いた文章にすることもできます。生成の雰囲気は、この選択方法によって変わります。
5)文が完成するまで繰り返す
選ばれた語が文に追加されると、再び次の候補が計算されます。この流れが繰り返され、ひと続きの文章としてまとまっていきます。単に語をつなぐのではなく、文脈を読み取った上で調整が加えられる点が特徴です。
生成AIの画像・音声・音楽生成の仕組み
画像や音声、音楽の生成は、テキストとは異なる形式のデータを扱うため、モデルの仕組みにも幾つか特徴があります。ただし「入力を数値化し、段階的に生成していく」という基本構造は共通しており、流れを追うと全体像が理解しやすくなります。
ここでは、データ形式ごとの特徴を図表3に示し、既に説明したテキスト以外について解説します。
対象 | 代表的モデル | 入力条件 | 生成の考え方 |
|---|---|---|---|
テキスト | LLM(Transformer) | プロンプト | 次トークン確率の逐次サンプリング |
画像 | 拡散モデル | テキスト埋め込みなど | ノイズ除去を反復して復元 |
音声 | Transformer/Vocoder | テキスト・話者特徴 | Transformerでメルスペクトログラムを生成し、Vocoderで最終音声波形を作成 |
音楽 | Transformer | ジャンル、テンポ、ムード、楽器 など | 音楽データの時系列的な流れから楽曲の骨格構造を構築 |
図表3:データ形式ごとの特徴
画像生成
画像生成の中心となっているのが、ノイズを徐々に取り除いて画像を形作る方式です。最初はランダムな状態から出発し、指示に合う方向へ少しずつ調整しながら形を整えていきます。
画像をそのまま扱うと計算が重くなるため、一度圧縮された空間に写してから処理する手法がよく使われています。
テキストと画像の内容を結び付ける仕組みも組み込まれ、構図や質感が指示に沿うよう調整されます。
音声生成
音声の場合は、波形やメロスペクトログラムと呼ばれる時間方向の特徴量を扱います。話者の声の特徴や発音の流れなど、時間とともに変化する要素が多いため、一定の順序で処理が進みます。
テキストから音声を作る場合は、まず発音情報にVocoderで変換し、そこから連続的な波形へつなげる工程を踏みます。最近は、ノイズを含んだ波形を整えていくモデルも登場し、滑らかな音が出しやすくなっています。
音楽生成
音楽は音の高さ・長さ・和音の組み合わせなど、多くの要素が重なって成立します。
メロディだけでなく、ジャンルや楽器、テンポやムードなどの条件を入力すると、それに合う展開を順に組み立てていきます。流れとしては時系列的な流れを学習データから全体的な楽曲構造を構築し、最終的には音楽合成器が音声データを生成する方式が使われています。
言語モデルに近い仕組みですが、音楽特有の構造を意識した扱いが行われます。
生成AIの応用的な使われ方とそれぞれの仕組み
生成AIは文章や画像を作るだけでなく、業務のさまざまな場面で応用されています。
ここでは代表的な四つの領域を取り上げ、それぞれがどのような仕組みで動いているのかを紹介します。
コード生成
コード生成は、自然言語の指示を基に関数やスクリプトのひな形を組み立てる仕組みです。プログラミング言語を文章と同じように扱い、次に続くトークンの確率を推定することで動作します。関数名や変数の関係を読み取り、その文脈に合う構造をまとめていきます。
補完だけでなく、既存コードの整理やテストケースの作成といった用途にも広がっています。
検索拡張生成(RAG)
RAGは、モデルの外側にある情報源を参照しながら回答を作る仕組みです。質問が与えられると、まず関連しそうな文書を検索し、その内容をモデルに渡してから生成を行います。
学習時点の知識に依存し過ぎないため、最新の情報や限定された社内データを扱う場面でも使いやすい特徴があります。
関連記事:AI技術「RAG」とは?仕組みや生成AIとの関係など分かりやすく解説
エージェント
エージェントは、生成AIが外部ツールと連携しながら複数のステップを順にこなす枠組みです。検索、計算、コード実行など、目的に応じて必要な行動を選び、結果を確認しながら次の動きを決めます。
単独の生成では処理しきれない複雑なタスクでも、段階を踏んで対応できる点が特長です。
パーソナライズ
パーソナライズは、ユーザーの嗜好や過去の行動を反映させて、応答の内容や語調を調整する仕組みです。履歴や属性をベクトルとして扱い、提示する情報の優先度や表現の細かい違いに反映します。
個々に合わせた出力が求められるサービスでの利用が進んでいます。
生成AIの学び方
生成AIを学ぶ際は、細かな理論から入るよりも、全体の流れをつかみ、小さな実践を通じて理解を深める方法が向いています。
まず、入力の前処理やベクトル化、確率に基づく生成といった基本構造を押さえると、各技術の関係が見えやすくなります。その上で、以下のようなステップを踏むと学びやすくなります。
- プロンプトの書き方を試し、応答が変わる理由を体感する
- トークン化や埋め込みの仕組みを図と合わせて理解する
- 画像や音声など、モダリティごとの生成の流れに触れる
- RAGや簡単なワークフローを自動化し、検索と生成の連携を経験する
基礎と小規模な実験を行き来しながら学ぶことで、生成AIの全体像を無理なく身に付けられるようになります。
生成AIの仕組みを正しく理解するために
生成AIの中心には、入力を数値として扱い、文脈に沿って候補を選びながら出力を組み立てる共通の仕組みがあります。テキスト、画像、音声、音楽といった対象が変わっても、この枠組みを土台に多様な応用が広がっています。
基礎となる概念を押さえておくことで、実践の場面でも動きの理由をつかみやすくなります。この記事で触れた流れを踏まえながら、興味のある領域から学びを深めてみてください。
■参考文献・出典■
- Attention Is All You Need|arXiv
- The Curious Case of Neural Text Degeneration|arXiv
- Denoising Diffusion Probabilistic Models|arXiv
- High-Resolution Image Synthesis with Latent Diffusion Models|arXiv
- Learning Transferable Visual Models From Natural Language Supervision|arXiv
- Robust Speech Recognition via Large-Scale Weak Supervision|arXiv
- Simple and Controllable Music Generation|arXiv
- Retrieval-Augmented Generation|arXiv
- ReAct: Synergizing Reasoning and Acting in Language Models|arXiv
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!















































-portrait.webp)





























