スキルアップNEW
【連載】要求工学における「利用状況」の扱いをめぐる考察:AIシステム要求定義のフロンティアを切り開くコンテキスト・エンジニアリング(第5回①)~「静的な完全さ」の限界:エージェント型AIシステムが形を変えて問い直す、「フレーム問題」のパラダイムチェンジ~

イントロダクション: 生成AI時代の要求定義
生成AIのプロンプト作成は、AIシステムへの要求定義そのものです。自然言語による質問や指示により、システムに期待する振る舞いをするように要求しているからです(図表1)。(本稿では、知識ベースの進化系という側面よりも、何らかのタスクを遂行してくれる側面にフォーカスします。)
現状(2025年10月現在)はAIシステムが期待通りの結果を返してこないので、さっさと見切りを付けてしまう人もいるようです。
しかし、「要求定義に失敗すると、期待通りの結果が得られないこと」は、開発に携わったことがある人であれば、誰でもよく知っていることでしょう。
期待通りの結果が得られないのは、AIシステムの出来が悪いのではなく、プロンプトの質が悪いからなのかもしれません。
従来の要求定義手法を適用して、漏れなく、誤解なく要求が伝わるようにプロンプトをブラッシュアップしていくと、それに応じて期待通りの出力が得られるようになっていきます。これはデバッグしているときの感覚にも似ています。
だからといって、どこまでも従来の要求定義と全く同じ考え方で、質の良い要求定義(プロンプト)を目指していては、従来技術でも実現できるシステムが出来上がってしまうことになります。それでは、せっかくのAIの能力をうまく引き出せているとは言えません。

そこで本稿では、従来の要求定義と共通している領域と、生成AIの良いところを引き出すために従来とは思考方法を変えるべきところと、その勘所を整理します。
また、最近プロンプトエンジニアリングに代わるであろうものとして注目を集め始めているコンテキスト・エンジニアリング[1][2]について、従来の要求工学の手法との関係を明らかにすることで、本質的にどこが新しく、なぜ必要とされているのかを説明します。
従来の要求工学の限界: 「完全な計画」の呪縛
本連載の第3回でBDDのプラクティスを幾つか紹介しました。その中で紹介した要求定義方法では、必要な実例を挙げた上で、そこからルールを導き出す必要がありました。
仮にExample Mappingなどの場で、そのルール化をサボったとしてみましょう。実例だけあればテストケースなら書けます。しかし、プログラムは書けません。ルールを明確化することなくコーディングできないからです。つまり、プログラムを書く時までには結局ルール化までしなければならないのです。
それに対して生成AI(LLM)は、期待値を含む実例をそのまま示して(このプロンプト手法にはFew-Shotという名前が付いています)、他の期待値が空欄の実例を与えれば、その空欄に対してもおよそ期待通りの結果を返してくれます。
一方で、敷居が低くなったのは、推測しやすい典型的な領域の話である、ということを忘れてはなりません。特殊なケースや例外的なケースの領域に入ると、うまく推測することが期待できないからです。
LLMは原理的に確率の高い、つまり通常起こる事柄(レギュラリティー)を推測することは得意ですが、特殊や例外的な(レアな)ケースを正確に扱えるわけではありません。
関連記事: LLMと生成AIの違いとは?それぞれの仕組みやできることを解説
従来からプログラム開発については、経験則としての「80:20」説*1がいわれてきました。
レアケースも含めて完全に期待通りに振る舞わせるようにプロンプトを追究し始めると、システム開発における要求定義の難しさと驚くほどそっくり同じ課題が出てきます。
結局のところ、抜け漏れなく誤解を生まない質の良い実例か、あるいはルールを用意することになります。これは避けられない問題であり、従来と何も変わりません。
抜け漏れなくルールを推測できるよう過不足ない例をそろえるのは大変であり、抜け漏れなくルールを正しく言語化するのと手間として大差なくなってしまいます。
また、仮想スクリプトエンジン(Virtual Script Engine)手法であれば、自然言語で伝えるよりもプログラミング言語風に伝えられることで、誤解を招かずに正確に表現できます。
言語化できるなら、従来通りのプログラム開発が良い方法だというのは間違いなさそうです。それならば従来通り、プログラムを書けばよいのではないかということになります。
実際には、プログラム開発の過程にAIが活用されています。「従来の要求工学の手法が不要」とはならないまでも、AIの支援で少しは楽ができそうだからです。
しかし、そんなことばかりをやっていては、AIを十分に有効活用したことにはなりません。
この思考パターンで考えている限り、開発して出来上がるシステムの方は従来の発想の範囲を超えるものにはならないからです。
確かにAIの活用は、生産性向上だけではなく、品質向上、技術者の学習支援など、さまざまな側面での効果が期待できます。
一方、AIとの連携による新たな機能の創出、利用状況の把握と学習結果をフィードバックした機能・品質強化といった側面、プロダクトを通して利用者に新しい価値を届けていくことも同時に考案しなければなりません。
しかし習慣とは恐ろしいもので、かなり意識的にやらないと従来と同じ思考法から抜け出すことが難しいのです。
開発対象やモデル化の範囲を、システムが期待通りに振る舞える範囲に限定しようとしてしまう癖、習慣が身に付いてしまっているならなおさらでしょう。
最初に目指すべきは、確実にシステム化が可能な範囲に期待をコントロールすることで成立する「完全な計画」だとしたら、そのような呪縛から逃れることが、生成AIから新しい価値を引き出す鍵になります。
そこで、本稿では従来のシステム開発の思考から脱却し、生成AIが切り開く新たな領域とは何かを整理したいと思います。
AIが切り開く新たな領域: 不確実性を取り込むシステム
従来、人工物への期待は、それが「予測可能で決定論的に振る舞うこと」を含んでいることが圧倒的に多いものである、と言ってよいでしょう。
対して、生成AIは確率的に振る舞います。それを困ったことであると捉えるか、望ましいことであると捉えるかは用途次第であり、使う側の期待やニーズ次第でもあります。
この関係を表の形で整理すると、図表2のようになります。

ユーザーの期待とシステムの振る舞いが一致しているので、(1), (4)には○を記入しており、(2), (3)は一致していないので×を記入しています。
先に説明した通り、多くの人工物の振る舞いは(1)に該当するでしょう。
データベースの検索機能のように複数のリストを示す場合でも、指定した条件を満たし、指定した並び順を守ってほしいため、リストとしてユニークな出力を期待していると考えられます。
(2)に該当するものとして、気象、株価、販売予測といったシステムが挙げられます。
正確な結果を返すとは限りませんが、それでも有益なシステムとして活用されています。
理想としては、正確な答えが欲しいわけですが困難なので、期待の方を下げ、許容の幅に収まることで折り合いを付けます。
つまり(2)の領域は、本来は(1)へ持っていきたくともできないため、代わりに(4)の領域に持っていっていることになります。
(3)に該当するものは、あまり思い付きません。
(3)の領域も期待と振る舞いが一致していないので(4)の領域に持っていく必要があります。しかし、それは多くの場合、容易に実現可能なので、(3)の領域に留まり続けていることがないからでしょう。
例えば、今日の夕食の献立を提案してほしい場合、毎回カレーを提案されてもうれしくはないので、幅を持った回答をしてほしくなります。とはいえ、その実現は、それほど困難ではないことが多いのです。
生成AIに対してこのことを当てはめてみると、確率的振る舞いをするため、表の(2),(4)の領域に該当します。
そこで本記事では、何の工夫もしないと×が付く(2)の領域に入ってしまうシステムを扱っていこうと思います。
先に(2)に該当する例に挙げた予測システムは、出力として当たる予測を期待しますが、現実に起こることは一つなので、理想としてはその現実に起こることを一つの予測として得ることを期待します。
実際は、以下の二つの理由で難しいと言えます。
(a) モデル化、法則化、ルール化、言語化の限界
検討すべき状況の因子が多過ぎたり、モデルが扱うべき因子を取捨選択する基準の設定が難しい
(b) モデルに与える各因子の初期値のノイズを取り除けない
カオス的なシステムは、仮に完全な決定性を持つモデルを作れたとしても、わずかなズレが大きく結果を変えてしまう(バタフライ効果)
LLMは、出力に確率論的なばらつきが起きることが主要な特性としてあります。
このため、カオス的な問題とも無縁ではありません。
確率論的な性質と内部の複雑な非線形性が組み合わさることで、カオス的な挙動を示す可能性があるといわれているからです。
LLMに与えるプロンプトのわずかな違いや、表現や句読点のわずかな違いでさえ、出力の全体的な内容を大きく変えてしまう現象が知られています。
気象予測のための因子を選定することが難しいのと同様に、人間の行動は、過去の経験、気分、周囲の環境、社会的な文脈など、無限とも言える要因(コンテキスト)に影響されます。
全ての要因を漏れなくモデル化することは現実的に不可能です。
状況は常に変化し、予期せぬ出来事(例えばパンデミックの急拡大、政治的な不安定化や政権交代など)が、予測に影響を与えます。事前に立てた計画は、こうした「動的な状況」には対応できません。
こういった困難があるにもかかわらず、現在、人間や組織、社会の中で、一部の仕事を任せられるようなさまざまなAIエージェントが実用化され始めています。
決定性や予測性を満たさないにもかかわらず、AIエージェントに仕事を任せて本当に大丈夫なのかという疑問が湧きます。
とはいえ、すでにさまざまな予測システムは有用で実用的なものとして成立しており、状況の変化に逐次追従しながらのシミュレーションや、統計処理を組み合わせることで有効性のあるものを生み出すことが実際にできています。
必ず正解を出すことが難しいとしても、次善の策として、振る舞いがある幅の範囲に収まってくれれば有益だからです。
図表2で、(2)を理想の(1)へは持っていけないため、(4)に持っていき、許容あるいは妥協可能な範囲や条件を明確化しています。
このためには、ステークホルダーと調整しながら折り合いの付くところを探す必要があります。
天気予測の例で考えると、時間と共に変化していく状況に逐次追従し、振る舞いを調整していく(例えば最新の条件で予測の再計算をするなど)仕組みを採り入れれば、次第に精度は高まり、正解にどんどん近づいていくことが分かるでしょう。
AIの領域でも、そのように状況に合わせて行動を変え、精度を向上させていく手法が提案されています。
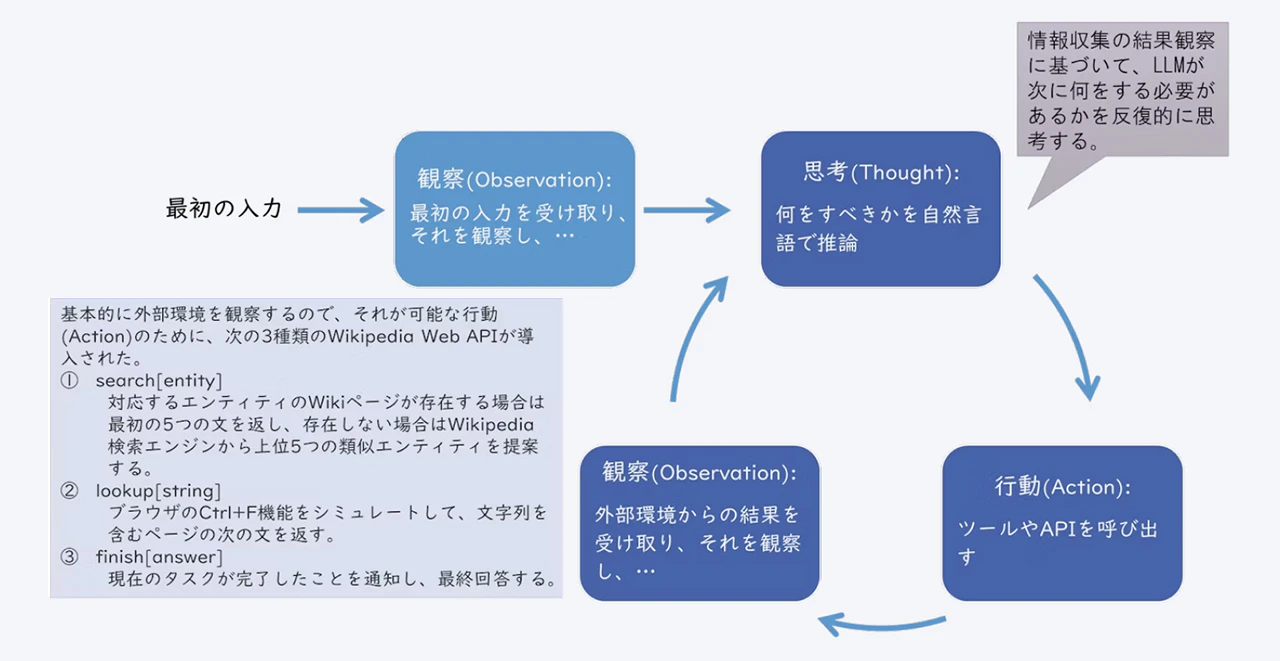
よく知られた手法の一つにYaoらの研究によるReAct[3]があります。
「Reason(推論)+Act(行動)」を意味するものとしてReActと名付けられ、以下の図表3に示すような振る舞いをします。
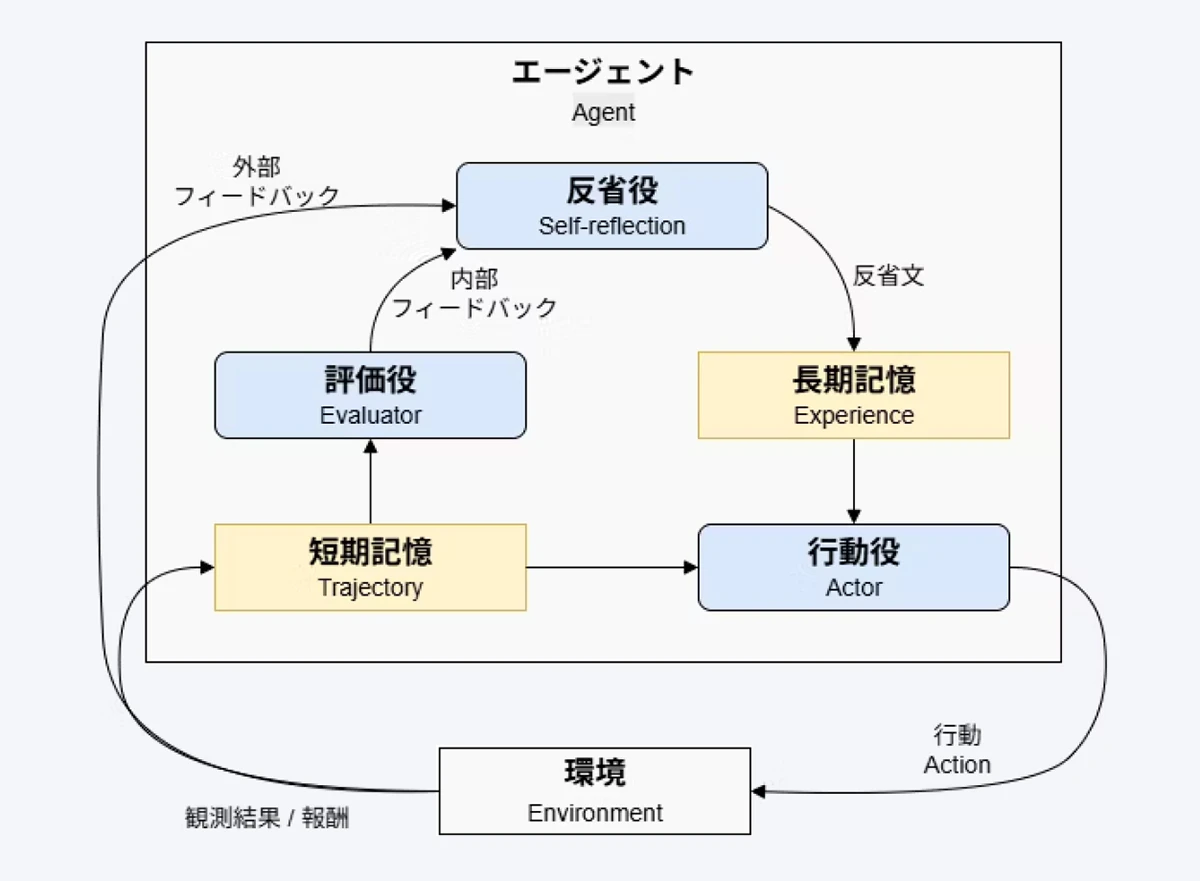
また、Shinnらによって成されたReflexionの研究[4]は、それを拡張したものと解釈できます。
Reflexionの重要なポイントは、実行結果を自己評価し、失敗した状況から学び、その反省を長期記憶に残すことです。
長期記憶も活用して常に次の行動を改善します。「内省(reflection)」を連想するReflexionと命名されていますが、図表4に示されている通り、外部の観察も含めての反省ということになります。
こうした仕組みを取り込むことで、AIエージェントは、その精度を高めていくことができます。
特に、観察対象にシステムの外部を含められること、またその際の因子を、従来のシステム設計時のようにあらかじめ限定しなくてよいところが、画期的だと思います。
これによって、先に挙げた二つの困難をかなり克服できます。
従来のシステムも、刻々と変化する状況を把握するために、繰り返し入力を求めたり観察を繰り返したりという仕組みは取り入れてきました((b)の困難への対応)。
ただし、何を観察するか、何を入力として受け付けるかは、その動作時ではなく、設計時には限定されている必要がありました。
第5回の前編はここまでとなります。後編では、生成AIの成功の前後で、アプリケーションシステムの設計において、どのような本質的な違いが出てきたのかを考察します。
注釈
*1)ソフトウェア工学の中でも議論の分かれるところであり、「レギュラリティー vs 例外処理の比率」については、明確な定量的データが把握されているわけではありません。プロジェクトの性質・業務ドメイン・設計思想・開発規模などによって異なっていることでしょう。エンジニアや設計者の間で、通常処理が約20%、例外処理が約80%の工数を占めるという経験則が語られることが多々あります。
参考文献
[1] Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, Shenghua Liu, 「A Survey of Context Engineering for Large Language Models」, https://arxiv.org/abs/2507.13334
[2] 林祥一, 「6W2Hで体系化し直した生成AI(LLM)のプロンプトの書き方 - 求められるのはプロンプトよりもコンテキストエンジニアリング」, Qiita, https://qiita.com/sho1884/items/a7c1aee2899c369ef6d6#%E6%B1%82%E3%82%81%E3%82%89%E3%82%8C%E3%82%8B%E3%81%AE%E3%81%AF%E3%83%97%E3%83%AD%E3%83%B3%E3%83%97%E3%83%88%E3%82%88%E3%82%8A%E3%82%82%E3%82%B3%E3%83%B3%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0. Accessed Oct 20, 2025.
[3] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan, 「Tree of Thoughts: Deliberate Problem Solving with Large Language Models」, https://arxiv.org/abs/2305.10601
[4] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao, 「Reflexion: Language Agents with Verbal Reinforcement Learning」, https://arxiv.org/abs/2303.11366
この記事を書いた人

執筆
林祥一
株式会社ベリサーブ ソフトウエア品質コンサルティング部。 1989年、NTTソフトウェア入社。交換機の性能検証、情報資源辞書システム(IRDS)の開発に従事。1991年、富士ゼロックスのシステム技術研究所に入所。オブジェクト指向言語拡張によるマルチエージェントシステム, CSCWの研究に従事。1998年に試作システム商品化のため開発部門に異動。以降、文書/記録管理・コラボレーション支援・ワークフロー・内部統制・エンタープライズリスク管理などのプラットフォーム開発のアーキテクトおよび商品企画に従事。また一時期、iDCの運用設計にも従事。2010年にHAYST法をお客様に伝授する役目を担ったことをきっかけに、コンサルティング活動を開始。2018年ベリサーブ入社。 ※執筆者の所属、肩書などは執筆当時のものです。
この記事は面白かったですか?
今後の改善の参考にさせていただきます!











































-portrait.webp)





























