ナレッジNEW
生成AIの問題点とは?トラブル事例や解決策も解説

目次
生成AIの活用は、業務効率化や学習支援に役立つ一方で、著作権や個人情報、倫理面など多面的なリスクを抱えています。導入を進める企業や教育機関では、メリットだけで判断するとトラブルを招く恐れがあるため、まず生成AIを活用する上での問題点を正しく理解することが大切です。
本記事では、生成AIの具体的なリスクや事例、トラブルを避けるための考え方を整理し、安全に活用するためのポイントを解説します。
生成AIが抱えるリスクの種類
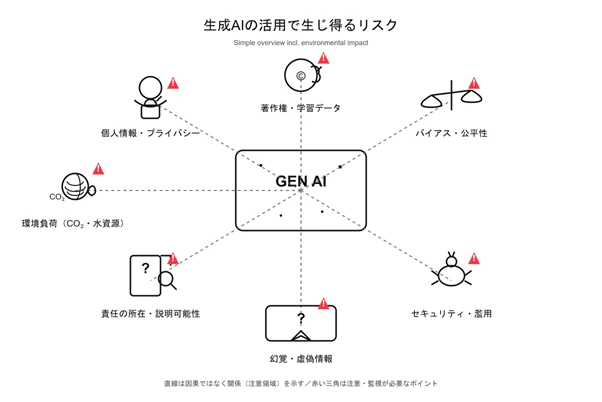
生成AIには、技術面・法制度・運用体制など、幾つかの異なる領域でリスクが存在します。
そこで図表1に、本記事で扱う主なリスクと、代表的な事例・対策の方向性をまとめました。
リスクの種類 | 概要 | 例 | 対策の方向性 |
|---|---|---|---|
著作権・肖像権 | 学習に使われたデータの扱いで権利面の問題が起きる | 特定作品に似た画像が生成される | 学習データの出所確認、利用範囲のルール設定 |
プライバシー・個人情報 | 出力内容に個人情報が混ざる恐れ | 生成文に実在人物の情報が含まれる | 入力データの制御、ログ管理、出力管理 |
ハルシネーション | 誤った情報を事実のように示す | 存在しない法律や論文名を回答する | 人による確認プロセスの確保 |
倫理 | 不適切な表現や偏りが出る可能性 | 差別的な表現が出力される | 利用ポリシーの整備、出力管理 |
セキュリティ | AIが攻撃対象・攻撃手段として使われる | プロンプトインジェクション | アクセス制御、モデル設定の管理 |
データ汚染 | 改ざんデータが学習に混ざるリスク | ポイズニングによる性能低下 | 学習データの検証、異常検知 |
環境負荷 | 運用時の電力消費が大きい | 大規模モデル利用時のCO2排出や水資源への影響 | 軽量モデルの活用、クラウド設定の最適化 |
図表1:生成AIの主要リスクと主な対策
生成AIにまつわるリスクは、大きく分けて技術面、法制度や倫理、そして運用体制の三つに分かれます。これらは著作権の課題がセキュリティと関係するように、幾つかの領域が重なり合う点が特徴です。こうしたつながりを理解しておくと、導入時に気を付けるべきポイントが整理しやすくなります。図表2に、そのイメージ図も示します。
生成AIの問題点1)著作権・肖像権の問題
生成AIを語る上で、最も議論になりやすい領域が著作権と肖像権の扱いです。
概要
著作権の問題は、モデルの学習過程で利用されるデータの扱いと密接に関係しています。
生成AIは大量の画像や文章のパターンを学習しますが、その中に著作物が含まれている場合、権利者の許諾がないままデータを使ったと見なされる恐れがあります。特に画像生成モデルでは、既存作品と似た表現が生まれるケースがあり、生成物の独自性や著作権上の扱いが曖昧になりやすい点が指摘されています。
また、Web上で公開されたデータはライセンスや再利用条件がまちまちで、取得元が不明確なまま学習に使われた例も報告されています。
事例
代表的な例として、Getty ImagesがStability AIを提訴した件が挙げられます。Getty Imagesのロゴが入った画像が生成され、許諾のない学習利用が問題になりました。
また、米国では複数のクリエイターが画像生成モデルを対象に集団訴訟を起こし、著作物の無断学習が争点となっています。
文章生成の分野でも、書籍データの許諾の有無が議論され、透明性の確保が求められています。
対策・解決策
データの出所が明確なモデルやサービスを採用することが基本的な対策になります。近年は、著作権処理済みデータセットを用いた生成AIも増えており、透明性のあるサービスを選ぶことでリスクを抑えられます。
次に、生成物の扱いに関する以下のようなルールづくりが重要です。
- 外部公開前に類似性をチェックする
- 生成素材をそのまま納品物にしない
- 人による確認フローを設ける
こういったルールをあらかじめ設けることで、組織的な対応が行えます。また、自前データや著作権クリアな素材を学習やプロンプトの補助に使う方法も、現場では取り入れやすい手段です。
生成AIの問題点2)プライバシー・個人情報の問題
生成AIを使う場面で、個人情報やプライバシーが漏れてしまう恐れがある点にも注意が必要です。
概要
生成AIは大量のテキストや画像を学習しますが、その中に個人を特定できる情報が含まれていた場合、出力に影響する恐れがあります。
また、利用者が入力した内容が保管され、サービス側の改善に使われる仕組みも多く、社内文書や個人情報を誤って入力すると第三者に見られる形で残る可能性があります。学習データと利用時の入力の双方にリスクがある点が特徴です。
事例
ある調査によれば、生成AIチャットボットを使っていた利用者のやりとりが「共有」機能を通じて第三者に見られる形で公開されていたと報告されています。これにより、意図せず個人情報が外部に流出したケースがあるとされます。
また、企業の従業員が社内文書や機密情報を生成AIに入力した結果、その情報が外部に漏れた事例もあります。
さらに、生成AIの訓練時に収集されたデータの中に医療記録やソーシャル情報などの敏感な個人情報が含まれていたという指摘もあり、従来のデータ処理技術(データのスクリーニングなど)だけではプライバシーが守られない可能性があると報告されています。
対策・解決策
入力してよい情報の範囲を明確にし、個人名や機密情報を扱わない運用ルールを整えることが基本です。
サービスを選ぶ際は、ログ管理の方針やデータの保持期間を確認し、社内外に共有する前には内容を必ず人が確認します。
必要に応じて、匿名化やデータマスキングを併用し、モデルが扱う情報量を最小限に抑える方法も取れます。
生成AIの問題点3)ハルシネーション(虚偽情報)の問題
生成AIはもっともらしい文章を作る性質から、誤った情報を自然な形で示してしまうことがあります。
概要
ハルシネーションとは、生成AIが根拠のない情報を事実のように提示する現象です。モデルは学習データの傾向に基づいて文章を組み立てるため、回答内容が正しいかどうかを判断しているわけではありません。
結果として、存在しない制度や論文名を出したり、事実と異なる数字を提示したりするケースが起こります。特に専門分野では、その専門分野に詳しくはない利用者が誤りに気付きにくい点が問題です。
事例
代表的な例として、実在しない判例や書籍を示してしまい、利用者が誤情報を引用する事態が報告されています。
法律分野では、生成AIが「存在しない裁判例」を提示し、弁護士がその内容をうのみにしてしまったケースが話題になりました。
学術分野では、架空の論文名や著者名を回答した例が複数指摘されています。
対策・解決策
生成AIの回答を一次情報で必ず確認する運用が必要です。
法律・医療・学術など正確性が求められる分野では、公式文書、自治体ページ、論文データベースなどの信頼できる情報源を併用し、生成AIの回答だけを判断材料にしないことが重要です。
企業や教育現場では、生成AIの利用範囲を明確にし、重要な判断を伴う分野では参考情報として扱うにとどめる体制が現実的です。加えて、モデルのバージョンやアップデート内容を把握しておくことも、情報精度を確保する上で役立つでしょう。
生成AIの問題点4)倫理的な問題(バイアス・差別)
生成AIには、学習データの偏りがそのまま出力に影響しやすいという課題があります。
概要
生成AIは、大量の文章や画像から傾向を学習する仕組みですが、そのデータに偏りが含まれていると、出力内容にもバイアスが反映されてしまいます。特定の属性を不当に結び付けたり、無意識の差別表現が混ざったりするケースがあり、利用者が気付きにくい点が問題です。
また、生成AIが「中立で客観的」と誤解されることもあり、出力への依存が強まるほど、偏った情報が広がるリスクが大きくなります。
事例
海外では、画像生成AIが特定の職業を特定の性別ばかりで描写してしまう事例が確認されており、学習データの偏りがそのまま反映されたと指摘されています。
米国立標準技術研究所(NIST)は、生成AIの学習過程で生じるバイアスが差別や誤解につながる可能性をまとめ、注意喚起を行っています。
対策・解決策
対策として、学習データがどのような属性で構成されているかを把握できるモデルやサービスを選ぶことが重要です。企業で利用する場合は、生成内容に偏りがないかを確認するチェックフローを設け、人物や職業などに関する出力は必ず人が目を通す体制が必要です。
利用者側でも、生成結果をそのまま採用するのではなく、複数の視点から内容を見直す姿勢が欠かせません。必要に応じて出力条件を調整し、偏った表現が続く場合はプロンプトの修正や別サービスとの併用など、運用面での工夫が求められます。
生成AIの問題点5)セキュリティの問題
生成AIは、入力内容やモデル自体が攻撃対象になる点が課題です。
代表的なものに、AIへ意図しない動作をさせる「プロンプトインジェクション」があり、外部に公開したチャットボットが想定外の回答を返したり、内部情報に触れてしまったりする事例が報告されています。
社内システムと連携させる運用では、AIを経由した情報漏えいのリスクも考慮が必要です。
対策としては、APIの権限設定やアクセス制御を細かく管理し、モデルに渡す情報量を最小限に抑える運用が現実的です。
さらに、ガードレールの適応も視野に入れる必要はあるかもしれません。併せて、公開前に挙動を検証し、予期しない動作が起きないかを確認する手順となるレッドチーミングのような仕組みを設けておくと安全性が高まります。
生成AIの問題点6)学習データとデータ汚染の問題
学習データに不正確な情報や悪意あるデータが含まれると、モデル全体の品質が下がる恐れがあります。
悪意のある入力によってAIを誤学習させる「データポイズニング」と呼ばれる手法も確認されており、改ざんデータが混ざると、出力の精度や判断の一貫性が損なわれる点が問題です。
対策としては、出所が明確で信頼性のあるデータセットを採用し、学習前後で異常値や偏りを検出する仕組みを取り入れる方法が有効です。
自前データを使う際は、収集段階で重複や不整合を取り除き、データを定期的に更新する運用も欠かせません。
生成AIの問題点7)環境負荷の問題
大規模生成AIの学習や運用には多くの電力や冷却のための水が大量に必要とされ、CO2排出量の増加や水資源への影響が指摘されています。
研究報告によれば、巨大モデルの学習だけで一般家庭の数年分に相当する電力を使う例もあり、エネルギー面での負荷が無視できない規模になっています。
対策としては、必要以上に大きいモデルを使わない、処理量の少ない軽量モデルを活用する、クラウド側の省エネ設定や再生可能エネルギーを利用するサービスを選ぶなど、運用面で調整しやすい方法があります。
また、推論回数を抑えるワークフローを設計することも、エネルギーや水消費の抑制に役立ちます。
【現場別】生成AIの問題点と検討したいポイント
生成AIの課題は共通していても、教育現場と企業では直面するリスクが異なります。ここでは、それぞれの場面で気を付けたいポイントをまとめます。
教育現場
教育の場では、生成AIが学習プロセスを短縮し過ぎてしまう点が問題です。リポートをAIに任せると、考える機会が減り、知識の理解が浅くなる恐れがあります。
さらに、生成AIが誤った内容を自然な形で示すと、学習者が真偽を判断できず、そのまま宿題やリポートなどの提出物に取り入れてしまうケースもあり得ます。
対策としては、授業ごとにAIの利用範囲を明確にし、参照先の確認や比較検証を習慣化することが重要です。教員側でも、AIを使う目的を共有し、学習者が使いどころを誤らないようサポートする姿勢が求められます。
企業利用
企業では、生成AIへの入力から機密情報が外部に渡るリスクが大きいと指摘されています。
社内文書や顧客情報を誤って入力すると、サービス側に保存され、他者が閲覧できる形で残る可能性があります。生成物の著作権や品質管理も重要で、誤情報を含む資料を外部に出すと信用の低下につながります。
また、AIが作った文章をそのまま決裁に使うと、責任の所在があいまいになり、判断プロセスが不透明になる可能性がある点も課題です。
対策としては、入力してよい情報の基準を明確にし、出力は必ず人が確認するフローを組み込む方法が現実的です。AIを意思決定の代替ではなく、補助として扱う位置付けを保つことで、安全な運用につながります。
生成AIの問題点を理解し、安全に活用するために
生成AIは便利な一方で、著作権、個人情報、誤情報、バイアス、セキュリティなど多くの課題と向き合う必要があります。これらは一つずつ性質が異なりますが、仕組みや背景を理解しておくことで、導入時の判断がしやすくなります。
組織としては、利用範囲や確認フローを整え、人によるチェックを前提にした運用を続けることが重要です。リスクを知った上で使えば、生成AIをより安心して活用できるでしょう。(図表3)

■参考文献・出典■
- Getty Images issues statement on ruling in Stability AI UK litigation|Getty Images
- Image generator litigation · Joseph Saveri Law Firm & Matthew Butterick
- AI Chatbots Are Quietly Creating A Privacy Nightmare | Bernard Marr
- Nearly 10% of employee genAI prompts include sensitive data|CSO Online
- Exploring privacy issues in the age of AI|IBM
- Artificial intelligence and bias: Four key challenges|Brookings
- Artificial Intelligence Risk Management Framework (AI RMF 1.0)|NIST
- 生成AIサービスの利用に関する注意喚起等について |個人情報保護委員会
- DeepSeek等の生成 AIの業務利用に関する注意喚起|デジタル社会推進会議幹事会事務局
- OWASP Top 10 for Large Language Model Applications|OWASP Foundation
- LLM01:2025 Prompt Injection - OWASP Gen AI Security Project
- Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models(arXiv)
- Energy demand from AI – Energy and AI – Analysis - IEA
- AI is set to drive surging electricity demand from data centres while offering the potential to transform how the energy sector works - News - IEA
- AIと著作権について|文化庁
- “General Understanding on AI and Copyright in Japan”|文化庁(英語版)
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!











































-portrait.webp)





























