ナレッジNEW
ビッグデータとは?活用事例や分析のポイント、AIとの関係について

目次
日々の生活やビジネスのあらゆる場面でアプリケーションやソフトウェアが利用されることにより、膨大なデータが生まれています。売上やアクセスログのような数値や文字だけでなく、画像や位置情報、センサーの連続データまで含めると、その種類は想像以上に幅広いものがあります。
こうした多様でかつ天文学的な大量データを整理し、意思決定やサービスに活用するためにも「ビッグデータ」を取り扱うためのアプローチや手法は、とても重要なものとなっています。
そこで本記事では、ビッグデータの基礎から活用事例、分析手法までを体系的にまとめます。
ビッグデータとは?
では、ビッグデータがどのような概念なのかを解説します。
単に「データ量が多い」というだけでは捉えきれない幾つかの特徴があります(図表1)。
そこで、以降ではビッグデータの定義や構造などについて説明していきます。

ビッグデータの定義
ビッグデータとは、既存のデータ処理方式やインフラでは扱いきれないスケール・速度・多様性を持つデータ群、あるいはそれらを活用するための技術やプロセスを含む広い概念です。
ここで強調したいのは、「ビッグデータかどうかは絶対量では決まらない」という点です。
リポジトリ(データレイク)に保管されている数十GBのデータより、共有メモリに入出力される1秒ごとに動的に更新する数MBのイベントデータの集合のほうが、運用の負荷や整備の難度が上がるケースは珍しくありません。ファイル形式も、表形式のデータにとどまらず、バイナリのログ、JSON、時系列、画像、音声、テキストなどが混在しています。
これらを一貫した品質で取り扱うには、取得・検証・変換・格納といった一連のパイプラインの設計が必要です。
また、ストレージ単価が下がることにより、データ量が増えたとしても「取りあえず全部保存しておく」という判断が起きがちです。一方、メタデータや来歴(リネージュ)管理が甘いと、検索も統制も効かないカオス化したデータの集合体になり、データとして利用しにくくなり、結果として使われないデータ群になってしまいかねません。
従来方式では限界を迎えるデータ構造
分かりやすく表すため、ビッグデータのことを「従来の前提を超える規模・速さ・多様性を持ち、扱う側の設計思想そのものを更新させるデータの集合」とイメージしてみてください。量・速度・形式のいずれかが突出しているわけではなく、それらが複合的に絡むことが本質的な特徴と言えます。
ビッグデータの特徴を整理した枠組み 3V(4V、5V)
ビッグデータの特徴を整理した枠組みとしてよく引用されるのが次の三つの頭文字Vで表した単語(3V)です。
- Volume(量)
- Velocity(速度)
- Variety(多様性)
この三つは、どの要素が複雑性を生むのかを言語化できるため、実務でも要件整理の指針として扱われています。
これに、Veracity(信頼性)を加えて「4V」、更にValue(価値)を加えて「5V」と説明されることもあります(図表2)。
観点 | 概要 | 主なデータ例 | 実務上のポイント |
|---|---|---|---|
Volume(量) | データ件数やサイズが巨大 | ログ、メディア、センサーデータ | 保存方針、圧縮、データレイクとDWHの役割分担 |
Velocity(速度) | 生成・流通・処理の速さ | ストリーミング、イベントログ | 遅延分布の把握、再処理手順、バッファ設計 |
Variety(多様性) | 構造化・半構造化・非構造化が混在 | CSV、JSON、画像、音声、テキスト | メタデータ管理、スキーマ進化への備え |
Veracity(信頼性) | データの品質やノイズ | 重複、欠損、外れ値 | 品質指標の定義、可視化、監査手順 |
Value(価値) | 活用によって得られる成果 | KPIとの関連 | ユースケース起点の優先順位付け |
図表2:5Vの整理
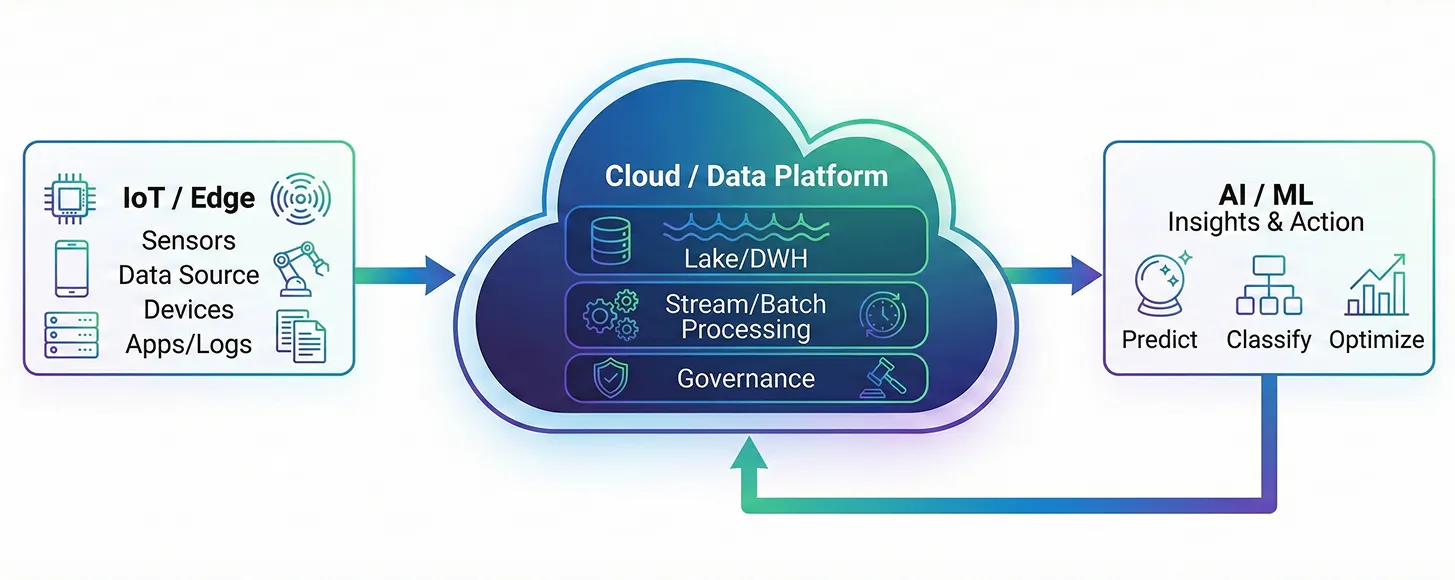
ビッグデータとAI(人工知能)・IoT・クラウドとの関係
ビッグデータは単体では価値を生みません。活用する技術とつながることで初めて価値が見い出せるようになります。特に関連が深いのが、AI、IoT、そしてクラウドです。
AIは、集めたデータからパターンを読み取り、予測や分類に生かす頭脳の位置付けです。十分なデータがあって初めて性能が発揮されるため、ビッグデータはAI活用の前提になります。
IoTは、製造機器やセンサー、アプリなどから日々データを生み出す「入り口」の役割を持ちます。クラウドは、その膨大なデータを蓄積し、必要に応じて処理するための土台です。保存容量や計算能力を柔軟に拡張できるため、ビッグデータとの相性が良い点が特徴です。
クラウドとは、『データを集める(IoT)→蓄積・処理する(クラウド)→活用する(AI)』
という流れでつながっています。この全体像を押さえておくと、ビッグデータを用いるシステムやサービスなどにおいて、どこに課題があり、どこからその解消に着手すべきかが見えやすくなります(図表3)。
ビッグデータの主な分析手法
ビッグデータの分析には多くの手法がありますが、本項では「記述・可視化による分析」「推測・機械学習による分析」「クラスタリングや異常検知」「テキスト分析」の四つに分類し、簡単に説明します。
記述・可視化による分析(現状把握)
最初のステップは、データの傾向や特徴を把握することです。
平均・割合・ばらつきなどの基本的な統計データを確認し、折れ線・棒グラフ・散布図などにより可視化します。異常に大きい値や欠損がないかを確かめることで、後続の分析の前提を整えられます。
推測による分析(予測・分類)
ビジネスでは、売上や需要の予測、離反(解約)の兆候検知など、未来を読む分析がよく求められます。そこで、回帰モデル、決定木、ランダムフォレスト、ニューラルネットワークといった機会学習より、データの特徴からパターンを学習します。
クラスタリングや異常検知(特徴でグループ化)
例えば、顧客を特徴ごとにグループ分けしたい場合にクラスタリングが役立ちます。教師なしデータの代表的なアルゴリズムで事前に指定したk個に分けたクラスタリングを行うk-meansや、固定効果と変量効果を共に含む統計学的モデルである混合モデルなどを使い、似た行動を示す顧客をまとめ、施策の方向性がつかみやすくなります。
設備の故障予兆やアクセス異常の検知には、距離ベース・確率ベースの手法が使われます。
テキスト分析(自然言語処理)
レビュー、問い合わせ、SNS投稿など、文章データの活用へも広がっています。固有表現抽出で語句を整理し、感情分析で肯定・否定の傾向をつかみます。
トピック分析や要約手法を使えば、多数の声を効率良く把握できます。図表4に、適用できるタスクとその手法を例示します。
タスク | 主な手法 | 評価指標の例 |
|---|---|---|
予測(回帰) | 線形回帰、木モデル、NN | RMSE、MAE |
分類 | ロジスティック回帰、木系モデル | AUC、適合率・再現率 |
セグメンテーション | k-means、階層クラスタリング | シルエット係数 |
異常検知 | 距離ベース、確率モデル | 再現率、PR曲線 |
テキスト分析 | 感情分析、要約、トピックモデル | F1、ROUGE |
図表4:タスク別の代表的手法
ビッグデータの身近な活用事例
次に、ビッグデータが日常のどんな場所で使われているのかを具体的に紹介します。業界ごとにデータの種類は異なりますが、共通しているのは「多様な情報を組み合わせ、より良い意思決定につなげている」という点です。
飲食業界の事例
飲食業では、POSデータ、予約情報、天候、周辺の人流などを組み合わせ、来店数や売上の予測に生かしています。予測結果を基に仕入れ量やスタッフの配置を調整することで、ムダの削減やオペレーションの安定につながります。
さらに、口コミやアンケートのテキスト分析から、満足度を左右する要因を抽出し、メニュー改善やサービス品質の向上に役立てる取り組みも広がっています。
医療業界の事例
医療現場では、電子カルテ、検査データ、画像、ウェアラブルデバイスの記録など、多種多様なデータが日々生まれています。これらを統合することで、診断支援や予後予測に用いる分析が可能になります。
また、リアルタイムのバイタルデータを基にした急変兆候の早期検知や、外来診療受付けでの混雑予測といった運営面の改善にも応用が進んでいます。データの機微性が高いため、匿名化やアクセス制御の設計が欠かせない点が特徴となります。
小売業界の事例
小売業では、購買履歴、在庫、価格、販促情報、オンライン行動ログなどを組み合わせ、需要予測や在庫の最適化に役立てています。顧客行動データから好みを推定し、レコメンドとして反映する取り組みも一般的です。
また、店舗内の顧客の動線や滞留エリアをカメラやビーコンで把握し、棚割りや売り場設計に反映する例も増えています。オンラインとオフラインをつなぐOMO(Online Merges with Offline)の設計には、データ統合の仕組みが欠かせません。
ビッグデータの分析ツール
ビッグデータを扱う際は、「どのツールを使うか」は成果に直結します。大量データの蓄積・処理・可視化にはそれぞれ異なる役割があり、目的に応じて適切な組み合わせを選ぶことが重要です(図表5)。
大規模データを保持しバッチ処理を行う基盤として大手企業のITインフラで広く用いられているのがApache Hadoopです。HDFS(分散ファイルシステム)による分散ストレージとMapReduceによる処理を組み合わせることで、膨大なログや履歴データの集計に向いています。一方で、運用や監視には一定の専門知識が求められます。
より高速な処理を必要とする場面では「Apache Spark」が選ばれます。インメモリでの処理によって計算が速く、バッチ・ストリーミング・機械学習を一つの基盤で扱える点が強みです。特徴量生成やリアルタイム分析など、柔軟なワークフローを組む場合に適しています。
クラウド環境を活用する場合は、フルマネージド型の「Google BigQuery」が有力です。インフラ管理を気にせず、SQLを中心に大規模データを分析できます。保存量やクエリに応じて課金されるため、コストを可視化しながら運用できる点も特長です。
可視化・共有の領域では「Tableau」のようなBIツールがよく使われます。ノーコードに近い操作でダッシュボードを作成でき、現場への共有までの距離が短いことがメリットです。データを使える形に変換して届ける工程に向いています。
区分 | 代表例 | 強み | 主な用途 | 留意点 |
|---|---|---|---|---|
分散処理/蓄積 | Apache Hadoop | 大規模データの蓄積・集計 | ログ処理、ETL | 運用・監視の知識が必要 |
汎用高速処理 | Apache Spark | 高速処理、ML/ストリーミング対応 | 特徴量生成、学習 | メモリ計画が重要 |
クラウドDWH | BigQuery | フルマネージドで拡張性が高い | SQL分析、共有 | クエリ・保存のコスト管理 |
BI/可視化 | Tableau | 視覚化・共有の容易さ | ダッシュボード作成 | ガバナンスとの調整 |
図表5:分析基盤とツールの比較
ビッグデータ活用で注意すべき課題
ビッグデータ活用には多くの可能性がありますが、その一方で注意すべき課題も存在します。
ここでは特に影響が大きいリスクを「個人情報保護」「セキュリティ」「データの偏り」に絞って解説します(図表6)。
個人情報保護
医療・小売・金融などの分野では、個人名や連絡先だけでなく、行動履歴や購買履歴などの個人を特定できる情報が含まれる場合があります。
そのため、個人情報保護法に基づいた取り扱いが欠かせません。収集目的を明確にし、必要以上のデータを扱わず、アクセス権を細かく管理することが基本となります。
また、分析に用いる場合は、匿名加工・仮名加工などの方法で再識別されるリスクを下げる取り組みが求められます。
セキュリティ
膨大なデータを扱うほど、外部からの攻撃や内部不正のリスクは高まります。ネットワーク、アプリケーション、データの各レイヤで多層的な防御の仕組みを整えることが重要です。
クラウド環境では、事業者と利用企業で役割が分かれる「責任共有モデル」を正しく理解しておく必要があります。暗号化、ログの監査、権限の分離、バックアップの体制整備が基本となります。
データの偏り
ビッグデータは量が多いため正確だと思われがちですが、実際にはデータの偏りが生じることがあります。例えば、特定の地域や属性に偏ったデータだけでモデルを学習すると、予測や判断がゆがむ可能性があります。また、欠損や重複、データの古さといった品質の問題が結果に影響する場合もあります。
そのため、データの分布や特徴を確認し、評価指標を複数組み合わせて検証することがデータの偏りを防ぐためには求められます。

ビッグデータ活用を成功させるには
ビッグデータは量の多さだけでなく、速度や多様性を持つため、その活用には品質管理まで含めた総合的な取り組みが求められます。ビッグデータから価値を生むためには、収集・蓄積・整備・分析・活用を一連のループとして捉え、ユースケース起点で検証しながら、段階的に基盤や運用を整えていくアプローチが有効でしょう。
■参考文献・出典■
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!











































-portrait.webp)





























