ナレッジ
ランダムフォレスト(回帰)とは?特徴や回帰・特徴量重要度も解説

目次
機械学習の手法は数多くありますが、実務で扱いやすく、安定した予測精度を得やすいアルゴリズムとして知られているのがランダムフォレストです。
用途としては分類だけでなく回帰にも対応し、需要予測や数値予測など幅広い場面で使われています。ソフトウェア品質分析や障害予測、需要予測、テスト工数見積もりといった品質データ活用の現場でも活用されており、実務との距離が近い点も特徴です。
一方で、仕組みや調整方法が直感的に理解しづらいと感じる方も少なくないようです。
本記事では、ランダムフォレストの考え方や構造、回帰での使いどころを解説します。
ランダムフォレストの主な特徴
ランダムフォレストには、次のような特徴があります。
- 多数の決定木を組み合わせて予測を行う
- 過学習が起こりやすい決定木の弱点を補いやすい
- 非線形な関係を自動的に捉えやすい
- 特徴量重要度を通じて結果の背景を確認できる
ランダムフォレストは、「多数の決定木を組み合わせて一つのモデルとして扱う」点が最大の特徴です。そのイメージを図表1で示します。
単一の決定木は構造が分かりやすい反面、学習データに過度に適合してしまい、過学習が起こりやすいという課題を抱えています。
ランダムフォレストでは、この弱点を複数の決定木の予測結果を統合することで補い、予測のばらつきを抑えます。
.webp)
非線形な関係を自動的に捉えられる点も特徴です。人手で複雑な特徴量を設計しなくても、データに含まれる関係性を学習しやすく、特徴量設計の負担が比較的軽くなります。
前処理として特徴量のスケーリングを行わずに扱われるケースも多く、欠損値や外れ値に対しても影響を受けにくい傾向があります。
学習後に特徴量重要度を算出できる点も実務では扱いやすいポイントです。予測結果そのものだけでなく、どの特徴量が結果に関与しているかを確認できるため、分析や考察の材料としても利用されています。
ランダムフォレストの構造
ランダムフォレストは、決定木、バギング、そして分割時のランダム性という三つの要素を組み合わせた構造を持ちます。これらがどのように関係し、モデル全体の安定性につながっているのかを説明します。
決定木との構造的な違い
決定木は、特徴量を条件分岐としてデータを段階的に分割し、最終的に予測値を出力するモデルです。構造が直感的で理解しやすい一方、1本の木だけで学習すると、特定のデータの傾向に強く引きずられやすい傾向があります。
そこでランダムフォレストでは、この決定木を複数生成します。
そして、木ごとに異なる視点でデータを見る構造にすることで、個々の決定木が持つ偏りを平均化しやすくしています(図表2)。
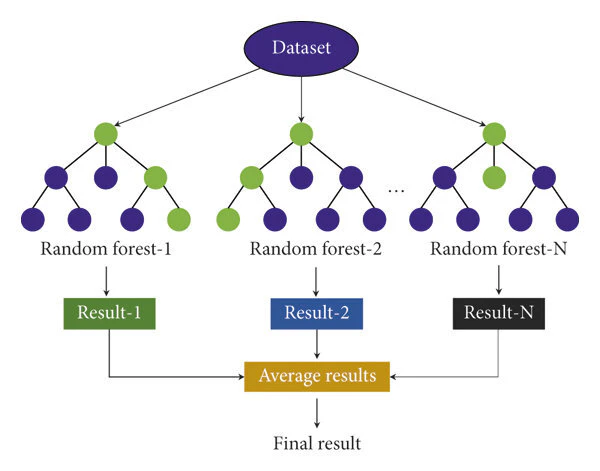
バギングとの関係
ランダムフォレストの土台になっている考え方が、バギング(Bootstrap Aggregating)です。バギングとは、元のデータセットから重複を許してランダムにサンプリングした複数のデータ集合を用い、それぞれでモデルを学習させた上で、結果を統合する手法を指します。
ランダムフォレストでは、このバギングによって作られた複数の学習データを使い、決定木を並列に学習させます。回帰の場合は各木の予測値を平均し、分類の場合は多数決によって最終的な予測を導きます。
この仕組みにより、特定のデータに依存した予測になりにくくなります。
誤差低減の考え方
ランダムフォレストでは、さらに分割時のランダム性が加えられています。各ノードで分割に使う特徴量の候補数をあらかじめ制限することで、常に同じ特徴量が選ばれる状況を避けます。
この工夫によって、決定木同士の似通い具合が抑えられ、予測誤差のばらつきが小さくなります。結果として、モデル全体としての分散が収まり、学習データが変わっても挙動が安定しやすい構造が保たれます。
ランダムフォレストを可視化する方法
ランダムフォレストは、内部で多数の決定木が動作するため、予測の仕組みが見えにくいモデルと捉えられることがあります。ただし、幾つかの可視化手法を使うことで、モデルがどのように判断しているかを把握できます。
以下に実務で使われることの多い代表的な指標である特徴量重要度を説明します。
特徴量重要度
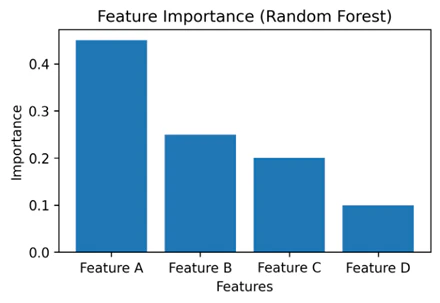
特徴量重要度は、各特徴量が予測にどの程度関わっているかを数値で示す指標です。ランダムフォレストでは、学習の過程でどの特徴量が分割に使われ、その結果として誤差がどれだけ減ったかを集計します。
分類問題ではデータセットの不均一性を測る指標であるジニ不純度、回帰問題では分散と平均二乗誤差を基に算出されるのが一般的です。
この指標を確認することで、モデルがどの変数を重視しているかが分かります(図表3)。品質分析や要因分析の場面では、予測結果そのものに加えて、背景にある要素を整理する手がかりとして使われます。
ツリー構造の可視化
ランダムフォレストに含まれる全ての決定木を可視化することは現実的ではありませんが、図表4のように代表的な1本を描画することで、モデル内部の判断の流れが確認できます。
ツリー構造を図として表示すると、どの特徴量がどの順番で使われ、どのような条件分岐が行われているかが分かります。
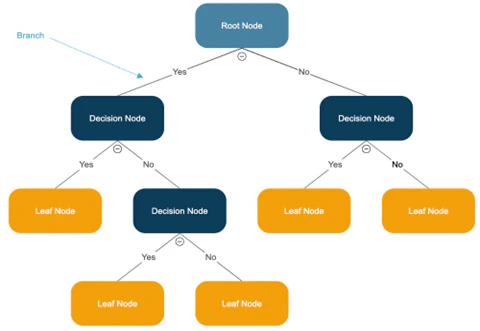
予測への影響を確認する別の可視化手法
特徴量重要度は全体的な傾向を把握するのに向いていますが、個々の特徴量が予測値にどのような影響を与えているかまでは分かりにくい場合があります。
そのような場合、特徴量の値を変化させたときの予測値の動きを確認する可視化手法が使われます。
例えば、ある特徴量だけを変化させ、そのときの予測結果の変化をグラフで表すことで、モデルがその変数をどのように扱っているかを直感的に把握できるようにします。
ランダムフォレストの精度を高める方法
ランダムフォレストの精度を高める際は、次のような観点から調整を行います。
- 決定木の本数を調整する
- 決定木の深さを制御する
- 分割時に使用する特徴量数を見直す
- 交差検証を用いてハイパーパラメータを探索する
ランダムフォレストの予測精度は、ハイパーパラメータの設定に大きく左右されます。決定木の本数を増やすと予測は安定しやすくなりますが、学習や推論にかかる計算量は増えます。決定木の深さを制限すると、学習データに過度に適合する状態を抑えやすくなります。
また、分割時に参照する特徴量数を調整することで、決定木同士の似通い具合が抑えられ、モデル全体のばらつきが小さくなります。
これらの設定は、グリッドサーチやランダムサーチを交差検証と組み合わせて評価することで、特定のデータ分割に偏らない形で検討できます。
【比較】ランダムフォレストと他のアルゴリズムの違い
図表5に、ランダムフォレストと代表的な機械学習アルゴリズムの違いを表にまとめ、それぞれについて説明します。
アルゴリズム | 主な特徴 | 調整の難しさ | 過学習への注意 | 向いている場面 |
|---|---|---|---|---|
ランダムフォレスト | 決定木を多数組み合わせて予測 | 比較的容易 | 比較的抑えやすい | 初期検証、安定性重視の予測 |
ExtraTrees | 強いランダム性を持つ決定木集合 | 比較的容易 | 抑えやすい | 分散を強く下げたい場合 |
勾配ブースティング | 誤差を逐次修正しながら学習 | 高い | 注意が必要 | 精度重視の回帰・分類 |
LightGBM | 勾配ブースティング系の高速実装 | やや高い | 注意が必要 | 高精度が求められる大規模データ |
深層学習 | 多層構造で複雑な関係を学習 | 高い | データ量に依存 | 画像・音声・自然言語処理 |
図表5:ランダムフォレストと他のアルゴリズムとの違い
ExtraTrees
ExtraTreesは、ランダムフォレストと同様に決定木を多数組み合わせる手法ですが、分割位置や特徴量の選択により強いランダム性を持たせています。そのため、分散を下げやすい反面、データによっては精度が安定しない場合もあります。
ランダムフォレストと近い性質を持ちつつ、挙動の違いを比較しやすいアルゴリズムです。
勾配ブースティング
勾配ブースティングは、前のモデルの誤差を次のモデルで修正する形で学習を進める手法です。精度面では強みがありますが、学習の進み方がデータに強く依存するため、過学習への配慮が欠かせません。
構造が比較的単純なランダムフォレストに比べ、挙動の把握には経験が求められます。
LightGBM
LightGBMは、勾配ブースティングをベースにしたアルゴリズムで、高速な学習と高い予測精度が特徴です。
一方で、学習率や木の構造に関するパラメータが多く、設定によっては過度に学習データへ適合しやすくなります。ランダムフォレストと比べると、精度を引き出すための調整負荷は高めです。
深層学習
深層学習は、多層のニューラルネットワークを用いて複雑な関係性を学習します。画像や音声、自然言語といった分野では高い性能を発揮しますが、十分なデータ量や計算資源が前提となります。
表形式データを中心とした予測タスクでは、構築や調整の負荷を踏まえると、ランダムフォレストの方が扱いやすい場面も少なくありません。
Pythonによる実装例
ここでは、ランダムフォレストを回帰問題で利用する際の基本的な実装例を紹介します。Pythonでは、機械学習ライブラリとして広く使われている scikit-learn を用いることで、比較的少ない記述でモデルを構築できます。
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)この例では、RandomForestRegressorを使って回帰モデルを定義し、学習データを用いて学習を行っています。決定木の本数や乱数の種を指定するだけでモデルを動かせるため、初期検証やベースライン作成にも使いやすい構成です。
まとめ
ランダムフォレストは、複数の決定木を組み合わせることで、予測の安定性と扱いやすさを両立した機械学習アルゴリズムです。構造が比較的シンプルで、回帰・分類の双方に対応できるため、初期検証から実務での予測モデル構築まで幅広く使われています。
特徴量重要度などを通じてモデルの挙動を確認しやすい点も、品質分析や数値予測の現場と相性が良い要素です。
精度だけでなく、調整や解釈のしやすさを含めたバランスの面で、ランダムフォレストは今後も実務で使われ続ける手法の一つと言えるでしょう。
■参考文献・出典■
Breiman, L. (2001). Random Forests. Machine Learning. scikit-learn公式ドキュメント
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!



























































-portrait.webp)


























