Technical Information
AIの品質における難しさを理解し先端技術で挑む

機械学習の技術を用いたAIシステムには、データを使った訓練によって機能を実装するという特性上、従来のソフトウェアとは異なる不確かさがあり、品質の管理・保証上の大きな課題となっています。本講演では、AIの技術的課題と品質に対する考え方の他、国内のAIの品質保証に関するガイドライン、将来を見据えた事例として、プログラム自動修正や自動運転分野における自動テスト生成の技術などを紹介します。
※この記事は、『ベリサーブ アカデミック イニシアティブ 2021』の講演内容を基にした内容です。

国立情報学研究所
アーキテクチャ科学研究系
准教授
石川 冬樹 氏
AIの難しさ
技術的限界と「不確かさ」
最初に、機械学習とは何かについて簡単に確認しておきましょう。機械学習はAIの一つの領域で、さまざまなデータの集まりから法則性を見つけ、それに基づいて予測や判別をする機能(計算式)を作ります。機械学習モデルの一つである深層ニューラルネットワーク(ディープラーニング)は、脳の仕組みを参考に作られており、何百万ものパラメータを用いて計算を重ね合わせます。近年、コンピュータの性能が向上したことで実用化が進み、画像や言語を処理する性能が飛躍的に向上しました。そうしてやってきたのが、第1次(1950年代)、第2次(1980年代)に続く、現在の第3次AIブーム(2000年代以降)です。
AIの素晴らしさについてはすでによく知られていますが、ここではその反対の側面の、難しさ・不確かさについて考えていきます。
テナガザルとパンダの画像を識別する例を見てみましょう(図1)。画像は、点ごとの色を表す数値の集まりで出来ています。この例ではテナガザルとパンダそれぞれのデータを見ながら、何百万ものパラメータを調整し、線引きをするための計算式を作ります。

図1:機械学習における画像識別の例
現在の画像識別の精度はとても向上しており、パンダの画像を与えるとAIは高い精度でパンダだと見分けます。しかし、人の目には見えないノイズを画像に加えると、「99%の確度でテナガザル」と判断する場合があります(図2)。
また、右の例のように「STOP」の標識に白や黒のテープを貼ると、AIはこれを別の標識だと誤認識するという実験結果も報告されています。このように、機械学習には技術的な限界があり、それ故に生じる性能や振る舞いの不確かさが話題となることがあります。

Ackerman, Slight Street Sign Modifications Can Completely Fool Machine Learning Algorithms, IEEE Spectrum’17
継続的な学習と社会的な要請
機械学習の技術的な限界の他にこんな出来事もありました。ある企業が開発したチャットボット(自動的に会話を行うプログラム)に対して、悪意を持ったユーザーが差別的な言葉や放送禁止用語を教え込んだ結果、AIがこれを学習してしまい、自ら不適切なメッセージを発信し始めました。開発者の手を離れたところで継続的に学習・更新し続けることが機械学習の機能なので、このような事態が起こり得るのです。また「悪意をもった攻撃」は論外としても、人の価値観は時代とともに変化します。AIを監視・制御するとともに、社会の要請を見据えた対応についても考える必要があります。
もう一つ、バイアス(偏り)の発生という課題もあります。これもある企業の話ですが、人材採用AIを導入したところ、女性に不利な雇用判断をしたのです。原因として、昔のデータは女性が少数であったため、女性固有の傾向を学べなかったり、女性に対する判断について十分に評価がなされなかったりした可能性もあります。古い時代のユーザーの潜在下にある差別意識や過去の採用比率の偏りをAIが学習してしまい、現在の社会では望ましくない差別的なバイアスを生じたのではないかと考えられます。第3次AIブームにより機械学習が普及する中で、開発者はこれらの課題にも向き合う必要があります。
従来のソフトウェアとの違い
従来のソフトウェア開発と機械学習を利用したソフトウェア開発は何が違うのかと考えたとき、私は「演繹」と「帰納」という言葉でそれらの本質を捉えられると考えています。
演繹とは、「ソクラテスは人である、人はいつか死ぬ、よってソクラテスはいつか死ぬ」といったように、一般論や規則を組み立てて結論を導き出す思考法です。従来のソフトウェアは、要求仕様に基づき、計算や判断を行うための知識・規則を人が決めてプログラムの形で書き下ろす演繹的システム開発です。これに対して、データを基に規則を類推するのが帰納であり、データから機能を作っていく機械学習は帰納的システム開発と言えます。「こういう動きをしなさい」という指示を人(エンジニア)が出していないところが、従来のソフトウェア開発との大きな違いです。
指示を出さなくても目的とすることが実現できるのはすごいことです。画像認識のように、規則性を言葉で書き出すことが困難な機能でさえも実現可能になります。例えば、自動運転の際の歩行者や信号の識別、工場における不良品などの検出、医療画像における腫瘍の発見、さらには複雑な条件の組み合わせが必要となるローンや保険に関する判断といった分野でも威力を発揮します。 一方で、機械学習には一般的な製品の品質保証と比べ、新たな労力を要したり、意思決定を困難にしたりする側面もあります。前述したように、原則として機能が不完全であること(100%正解することはあり得ない)。どの程度の性能になるかも作ってみるまで分かりません。新たな入力によってどう振る舞うかは未知であり、また、ある出力が起きた時に、なぜそうなったのかを正確に説明することができません。さらに、機械学習には大量かつ、「適切な」訓練データを用意する必要があります。
開発者が直面する課題
図3は、機械学習工学研究会が2018年に行ったアンケート結果です。機械学習の機能を含むソフトウェア開発がどのように難しくなるか、その課題意識を開発フェーズごとに質問しました。多くの回答者が、さまざまな開発シーンで「今までとは根本的に異なる考え方が必要」と考えており、「品質」に関わるフェーズでそれが顕著になっていることが分かります。

図3:機械学習を利用したソフトウェア開発における課題意識(フェーズ別)
課題の一例を挙げると、顧客との意思疎通については、予測性能について事前の約束ができないこと、誤った出力に対する論理的な説明が難しいことがあります。また、機械学習を活用したソフトウェア開発ではPoC(Proof of Concept)という概念実証のフェーズを入れることが多いのですが、そこで思うような成果を出せずに開発自体が打ち切りとなるケースも多く見られます。品質保証のフェーズでは、正解(出力の期待値)が用意できない、用意できるとしてもコストが膨大になる。また、同値分割のような場合分けや規則性では挙動を捉えられないなどの課題もあります。
AIの品質
ここからは、不確かさという特性を持ったAIの品質の評価について考えてみましょう。
図4に示したのは、工場などでの不良品検出の評価例です。このモデルでは500件の部品の中に不良品(陽性)が20件含まれている状態に対して、AIは45件を不良品と判定しました。検出の結果は次の4つの領域に分類することができます。
- ①不良品を不良品と判定(正解)
- ②不良品を良品と判定(見落とし)
- ③良品を不良品と判定(誤検出)
- ④良品を良品と判定(正解)
正しく判定できたのは①と④を足した465件(正解率93%)でしたが、この数字をどのように捉えるかは顧客の状況やミッションに依存します。
数字の一部分だけを捉えると、AIが不良品と判断した45件中の30件が良品だったということは、誤検出率は66%です。つまり2/3が判定の誤りだったことになります。ただ、現実の運用シーンでは、不良品判定をした部品は人が見て再判定すればいいので、②の「5件の見落とし」の方がより深刻な問題だと考えて優先度を高く設定し、怪しいものはとりあえず陽性とするといった判断が多く見られます。このように、誤検出と見落としの優先度やバランスについては、顧客のニーズを満たすように調整する必要があります。

図4:不良品検出の評価例
また、評価用データそのものに問題があるケースもあります。運用開始後、新たに生じた不良品パターンが評価用データに含まれていない場合、新しい不良品パターンを検出できるかどうかの評価は行われないため、実際に検出できるかどうかは分かりません。検出が必要な不良品パターンの画像データを大量に集めて高い正解率であったとしても、実際の運用時と異なる光の当たり方で、異なるカメラを使って集めたデータでは運用時と正解率が大きく変わってくる可能性があります。
「品質」を論じるためには、「500件のうち何件正解する必要がありますか?」「その500件にはどのような不良品パターンが含まれていますか?」「誤検出、見落としはどのように設定しますか?」など、会話を通じて顧客に問いを投げ掛け、評価の基準を明確にすることが必要です。このような機械学習を活用したプロダクトの評価に関する議論の要素がまとめられたガイドラインが存在します。
品質に関するガイドライン(1)〜QA4AIによるAIプロダクト品質保証ガイドライン
日本にはAIの品質に関するガイドラインが二つあります。一つはAIプロダクト品質保証コンソーシアム(QA4AI ※1)の「AIプロダクト品質保証ガイドライン」です。 QA4AIでは、品質を考えるべき対象として、成果物に関する三つの軸「訓練・評価するためのデータ」、「予測モデル(機械学習で作った機能)」、「システム全体(予測が誤った場合の制御を含むシステム全体のふるまい)」に加え、「プロセス(試行錯誤を繰り返すスピード)」、「顧客の期待(製品の目的に求められる期待値)」の計5項目についてのチェックリストのようなもの(評価の観点をまとめたもの)を提供しています。成果物とプロセスに対する評価が、顧客の期待に対してどのようなバランスとなっているかを確認するという使い方が想定されています。
AIプロダクト品質保証ガイドラインのチェックリストは多くの場合、そのまま使用するのではなく、評価対象ごとにカスタマイズが必要となります。現在、ガイドラインには自動運転、産業用プロセス、スマートスピーカー、画像・動画生成、AI-OCRという5ドメインに対してガイドラインを適用した評価事例が掲載されており、踏み込んだ分析が行われています。これらの情報を参考に、ガイドラインをカスタマイズしながら使い始める企業も増えてきています。
※1:Quality Assurance for Artificial-Intelligence-based products and services
品質に関するガイドライン(2)〜機械学習品質マネジメントガイドライン(AIQM)
もう一つのガイドラインは、国立研究開発法人 産業技術総合研究所が中心となってまとめた「機械学習品質マネジメントガイドライン
(AIQM)」です。
このガイドラインは、雲のようにファジー(あいまい)な認識対象に対して、図5の赤線に示されるような「場合分け」をすることでこれまでの品質保証に近い評価軸を検討しようという考え方に特徴があります。そのため、品質を語る上では、機械学習要素が対象とする動作範囲(想定データの範囲)を規定する必要があります。
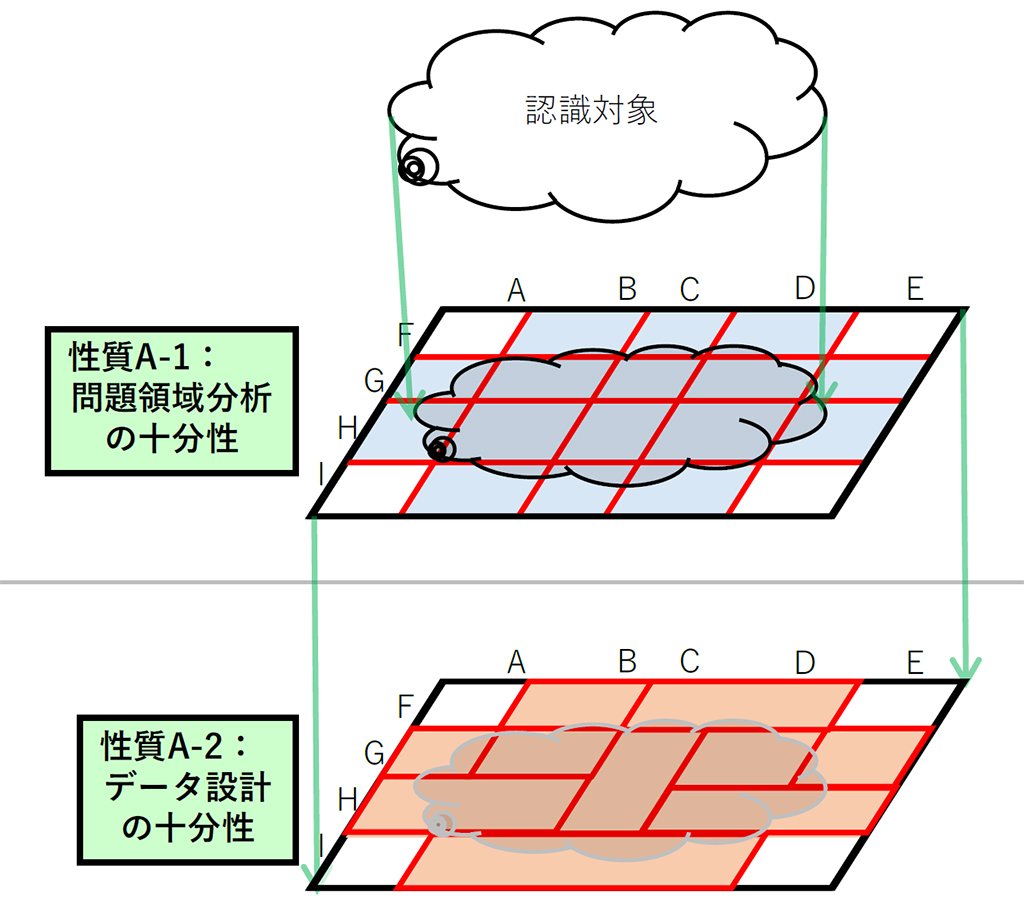
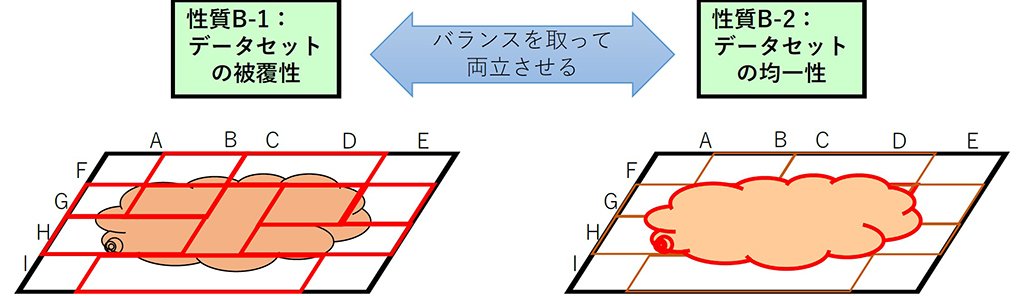
動作範囲を明確にすることをスタート地点として、「このケースのデータはあるか」といったデータ設計の十分性や、「集めたデータで足りるのか」、「レアケースをどこまで充実させるのか」といったデータセットの被覆(ひふく)性、「運用時の状況に合わせた自然なデータ分布となることを重視する」といったデータセットの均一性、さらには、学習データを準備するコストの面からそれらをどのようなバランスにするのかというような、データの品質を議論する上で必要な要素(図6)の他、機械学習要素の内部品質が体系的にまとめられています。
自動テスト生成・自動デバッグ技術の発展
ここからは、AIの機能を使ってテストを効率化する、品質を押し上げている「自動テスト生成・自動デバッグ技術」について紹介します。
Search Based Testing
代表的な例として「Search Based Testing」という技術を取り上げます。これは、作りたいテストを表すスコアを決め、最適化技術によって「より良い」テストケースやテストスイートを自動探索・生成するというものです(図7)。同じAIでも、データから学ぶタイプではなく、自動的に少しずつ実行条件を変更しながら試行錯誤を繰り返し、より良いものにたどり着くタイプで、進化計算やメタヒューリスティックとも言われます。この技術を用いた、よりカバレッジが高く、より数が少ないテストスイートを自動で生成するテストツールも登場しています。

図7:進化計算によるテストスイート生成のイメージ
AIプロダクトに対して、このSearch Based Testingを適用することも考えられます。前述した、試行錯誤を繰り返すタイプの進化計算AIを使用し、「望ましくない挙動」を最大化するという考え方で問題に至る入力を少しずつ変化させながら試行を繰り返し、より多くの障害を検出する手法が試みられています。これにより、同値分割などでテストケースを設計することが難しいAIプロダクトのテストの効率化が期待されています。
また、機械学習を用いた機能では、評価対象のデータが同じ場合、ニューラルネットワークにおけるニューロンの発火パターン(モデルを通る経路)は基本的に同じになります。ニューロンカバレッジを最大化するという考え方で、テストケースを変化させながら試行を繰り返し、ニューロンのさまざまな発火パターンを見つけ出します。このように、ニューロンの多様な挙動を促すことによって新たな失敗ケースを見つけることが可能になります。現在ではこうしたツールも登場し、企業からも注目されています。
自動デバッグ
品質向上のためには、もちろんテストだけでなく「修正する」ことも必要です。現在アカデミックの世界ではプログラムの自動修正に対する試みがなされています(図8)。Search Based Testingにより多様性や網羅性のあるテストを繰り返した際、コード内の通過箇所について統計分析を行い、バグが含まれる可能性の高いコードをリストアップします。一方で、Github ※2を見ると数多くのプログラマが行っているプログラムの修正パターンが分かります。修正パターン候補を順に適用して修正し、テストが正常になるまで繰り返すという方法です。こういったことがアカデミックの世界や企業で現在、研究されつつあります。
※2:Github社が運営するソースコードのホスティングサービス。バージョン管理やタスク管理などソフトウェア開発時に必要となる機能をクラウドで提供している。また、数百万ものオープンソースプロジェクトが存在し、ソースコードの修整履歴、課題やレビューなどの情報を取得することができる。

図8:Search Based Testingを用いた自動デバックの例
現在の研究事例 ~自動運転における展開~
最後に、私の研究室と自動車メーカーによる産学連携事例として、自動テスト生成/デバッグなどの研究を簡単に紹介します(図9)。
メーカーからは「自動運転におけるアクセル・ハンドルを決める経路計画プログラム」を提供してもらい、それに対して研究室では多様なシミュレーション設定(事故が起きやすい車の配置など)を探索していきます。車の配置や、一台一台の車のスピードなどを調整しながら、危険度の高い状況を探していくのです。
現在では、こうした試みをAIでも展開しようとしています。ただし、深層ニューラルネットワークでは、データを追加し再訓練すると100万個のパラメータが全部変わってしまいデグレにつながります。
これに対して、進行中の研究(「eAIプロジェクト ※3」)では原因箇所を絞り込むことで修正案を探索する方法を取ろうとしています。例えば100万個のパラメータのうち、失敗に大きな役割を果たしている10個のパラメータを推測し、そこだけを触って、他は一切触らない。そうすることで安定した修正が可能になると考えています。まだ進行中の研究ですが、将来に向けたチャレンジの一例です。
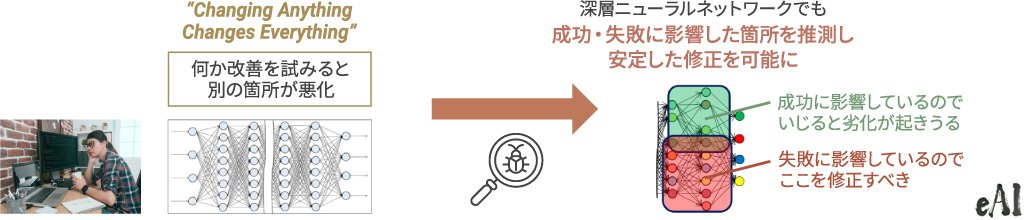
図9:自動テスト生成+自動デバックの展開に関する研究
※3:Engineerable AI プロジェクト(https://engineerable.ai/)
おわりに
AIというカタチでソフトウェアの能力が上がり、実世界や社会におけるインパクトが大きくなったために、品質に向き合う私たちの責任も大きくなったと言えます。大切なのは不完全さや不確実性を受け入れながら、ステークホルダーと議論することであり、また自動化できるところは速やかに対応して、迅速に試行錯誤を繰り返しながら探索・テスト・測定・監視による継続的進化を目指すことです。
今後も私たちアカデミックの研究者と企業の皆さまとで議論を深めながら、一緒に頑張っていきたいと思います。
この記事をシェアする