Technical Information
AIプロダクトの品質保証の概況と当社の取り組み

ChatGPTをはじめとする生成AIの隆盛を背景に、AIを組み込んだプロダクト開発・リリースが進んでいます。その一方で、AIプロダクトの品質をいかに確保していくかが問われています。本講演では、AIプロダクトの品質保証についての概況ならびに品質アセスメント、メタモルフィックテスティング、データ増幅などの当社取り組み事例について紹介します。
※この記事は、『ベリサーブ アカデミック イニシアティブ 2023』の講演内容を基にした内容です。

株式会社ベリサーブ
研究開発部長
須原 秀敏
AIプロダクトの品質に関する概況
深層学習の登場(2000年代)をきっかけに始まった現在の第3次AIブームですが、昨今の生成AIの登場とその飛躍的な普及を考えると、時代はすでに第4次AIブームに突入した感があります。
そしてAIの社会実装が進むと共に、その影響力や社会的責任も、より大きなものになりつつあります。負の側面に目を向けるなら、安全性や基本的人権を脅かす懸念もたびたび指摘されており、実際にAIに起因するインシデント事例が増加しているのも事実です。
■AIの特性
ソフトウェアシステムのプロダクトにおいて品質保証は非常に重要ですが、AIプロダクトの品質保証には少なからず困難が伴います。
しばしば指摘される例ですが、パンダの画像に図のようなノイズを加えると、AIはパンダを「テナガザル」と誤認識してしまうことがあります(図表1)。これは「よく学習したモデルでも、入力の小さな変化によって結果が変わってしまう」AIの特性を示すものです。このように、人間にとっては小さな変化でもAIにとっては大きな変化となるケースがあり、結果として人が予測しないような事態を引き起こし、時には社会の安全を脅かすことにもなりかねません。
ここにAIの品質保証の特異性と難しさがあります。

出典:Ian Goodfellow, Jonathon Shlens, Christian Szegedy, "Explaining and Harnessing Adversarial Examples", ICLR2015
図表1:AIがノイズを加えたパンダ画像を「テナガザル」と認識した
■AIの品質に関する規格
このようなAIの特性を背景として、現在、AIの品質に関わる各種の標準規格やガイドラインが国内外で多数公表されています)。
図表2は、その一例で、ISO/IEC規格の中から、「Trustworthiness(信頼性)」に関するワーキンググループが規定した国際規格をまとめたものです。
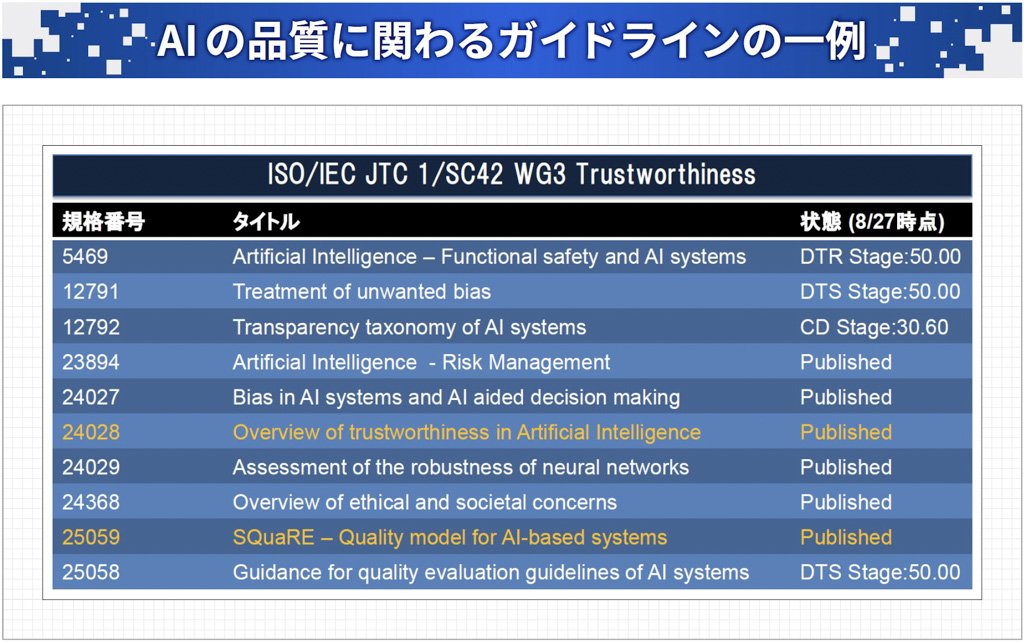
出典:ソフトウェア品質シンポジウム2023「AI搭載プロダクトの品質保証に関する国内外の動向と検証技術」小川秀人氏講演資料より(2023年9月8日)
図表2:ISO/IEC JTC 1/SC42 WG3 Trustworthiness
このうち特に重要なものとしてISO/IEC25059があります。これはAI特有の品質モデルを定義したもので、ベースとなるISO/IEC25010(SQuaRE=ソフトウェアにおける品質測定のための国際規格)をAI用に拡張したものになっています(図表3)。
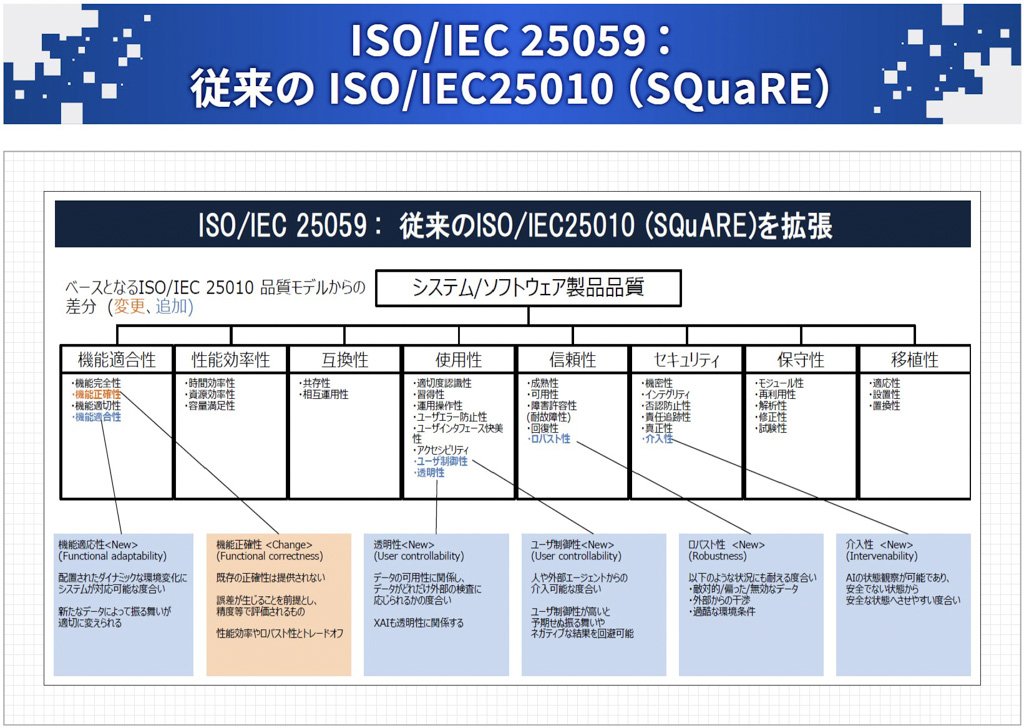
出典:ソフトウェア品質シンポジウム2023「AI搭載プロダクトの品質保証に関する国内外の動向と検証技術」小川秀人氏講演資料より(2023年9月8日)
図表3:青字がAIのために追加された部分
ISO/IEC25059では、従来のソフトウェア以上に考慮しなければならない項目として、機能適応性、透明性、ユーザー制御性、頑健性、介入性などが追加されています。
そして、AIプロダクトの品質保証もまた、こうしたAIならではの特性に対応して行うことが求められており、同時に当社の研究課題となっています。
AIの品質保証技法と当社の取り組み
ここからは当社の研究の中から、AIの品質保証に適応する手段・技法などについて紹介します。
まず、全体像を示したものが図表4になります。このうち、赤い破線で示した箇所(品質アセスメント、メタモルフィックテスティング、データ増幅)が、今回紹介する内容となります。
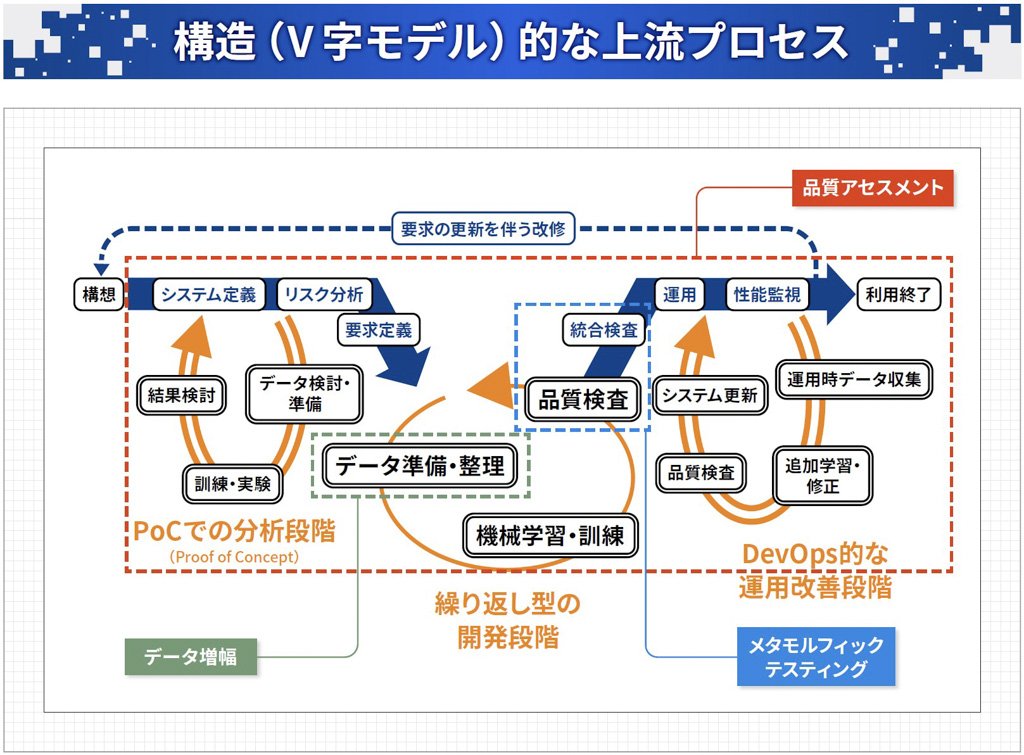
出典:産業技術総合研究所「機械学習品質マネジメントガイドライン 第2版」図6を基に、一部改変
図表4:AIプロダクトの開発全体における「品質アセスメント」、品質検査・統合検査に当たる「メタモルフィックテスティング」、データ準備・整備に当たる「データ増幅」を紹介する
■品質アセスメント
まずは 、最初の品質アセスメントになります。
AI品質保証の軸
品質アセスメントのベースになっているものは、AIプロダクト品質保証コンソーシアムがリリースしている「 AI プロダクト品質保証ガイドライン(以下 QA4AIガイドライン)」です。
QA4AIガイドラインでは次の5つをAIプロダクトの品質保証の軸としています(図表5)。
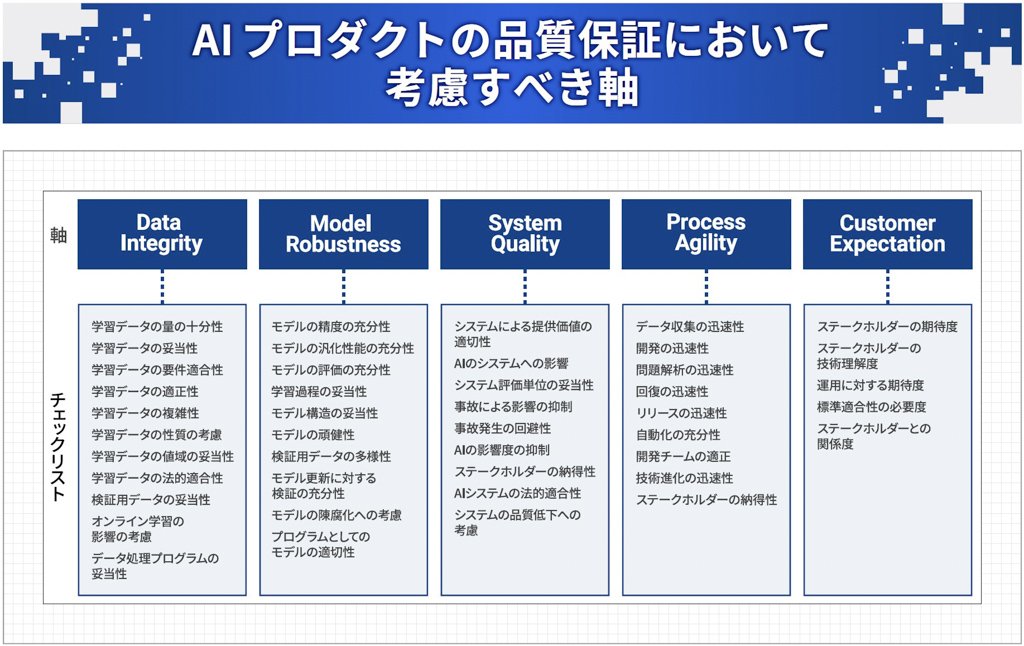
出典:AIプロダクト品質保証コンソーシアム「AIプロダクト品質保証ガイドライン2023.06版」より
図表5:5つの軸に対してチェックリスト(質問項目)が用意されている
- ・Data Integrity(データの完全性)
- ・Model Robustness(モデルの頑健性)
- ・System Quality(システム全体の品質確保)
- ・Process Agility(開発プロセスの機動性)
- ・Customer Expectation(顧客期待の高さ)
この5つの軸には、それぞれチェックリスト(質問項目)が用意され、個々にチェックしていくことでレーダーチャートを描き、各項目(軸)が十分に検討・対処されているかを視覚的に判断できるようになっています(図表6)。
左側のチャートでは、5つの軸についてバランスよく品質が担保されていることが分かります。また、右側のチャートでは、PoC~βリリース~継続的実運用と、各フェーズによって品質アセスメントの結果が段階的に向上していく様子を示しています。
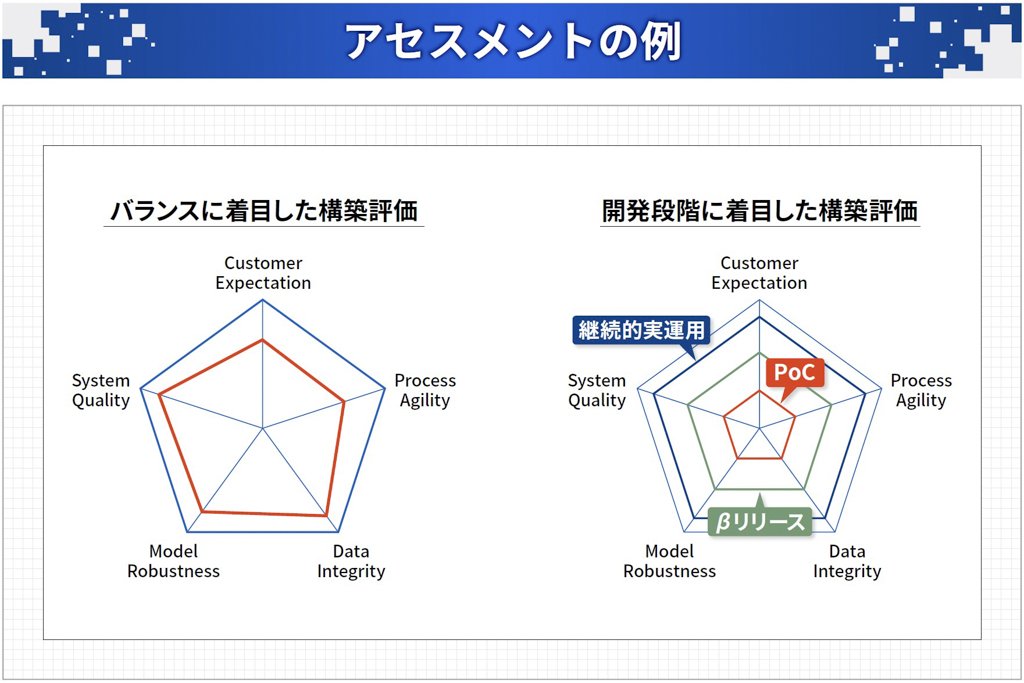
出典:AIプロダクト品質保証コンソーシアム「AIプロダクト品質保証ガイドライン2023.06版」より
図表6:レーダーチャートで表現することで、5つの軸のバランスが取れているか確認できる
フェーズごとの重要度の違い
このレーダーチャートにおいては、すべての軸が高評価となることがベストではありません。フェーズによって必要となる軸もあり、またプロダクトの特性によって必要になってくる軸も変化していきます。
フェーズごとの重要度の違いを各軸ごとに示したものが図表7です(重要なものほど濃い色で表現)。
例えば、PoC 設計のフェーズでは「Data Integrity(データの完全性)」や「Customer Expectation(顧客期待の高さ)」が重要となるので、そこに着目してアセスメントの取り組みを行っていきます。また、PoC評価のフェーズでは「Model Robustness(モデルの頑健性)」や「Process Agility(開発プロセスの機動性)」に注力してアセスメントの検討を行うことが求められます。
これを参考に、自分たちが今どこのフェーズにいるか、どこに着目してやっていくかを考えるベースとなるのがこのガイドラインです。

図表7:濃い部分の重要度が高い
■メタモルフィックテスティング
次に、メタモルフィックテスティングの概要と当社の取り組みについて紹介したいと思います。
メタモルフィックテスティングの基本
メタモルフィックテスティングとは、複数の異なる入力に対する出力結果を比較することで、テストオラクルなし、もしくは少ないテストオラクルで、プログラムのテストを行う手法です。テストオラクルとはテストケースの期待値を決めるための入力情報ですが、ソフトウェアによってはテストオラクルが用意できない場合があります。こうしたことからメタモルフィックテスティングは「オラクル問題の解決策」ともいわれます。
メタモルフィックテスティングの基本ですが、テストケースを増幅するという手法を取ります。
例えば、モデルにおいて、 x という 入力に対して f(x)という出力があると仮定します。これに対して x から g(x) へと変換を行ってモデルに入力し、f(g(x))という結果を得ます。そしてこのf(g(x))と 元のf(x) を比較することでテストケースを増幅します(図表8)。
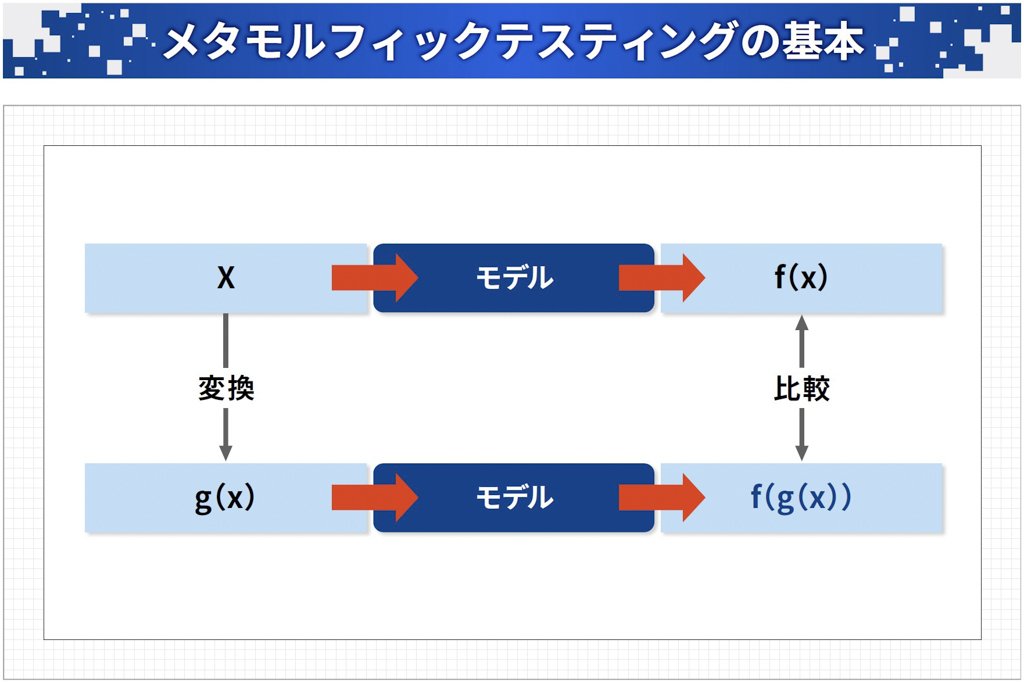
出典:国立情報学研究所「データ品質を利用したメタモルフィックテスティングによる 機械学習・深層学習モデルの評価」を基に当社作成
図表8:f(x)とf(g(x))はメタモルフィック関係となる
入力に対して変化を加えることで、入力を変換しない場合の出力=f(x)と、変換した場合の出力=f(g(x))を比較するわけですが、このf(x)とf(g(x))の関係性をメタモルフィック関係と呼びます。
例えば、人の顔を認識するようなソフトウェアにおいて、顔の画像(x)をモデル入力した場合に正しい認識結果・出力(f(x))が得られるのに対して、顔の角度が5度傾いた画像( g(x))を入力して同じ結果を得られるかどうかを比較します。この5度傾けても結果が変わらないというのがメタモルフィック関係であり、この手法を使ってテストを行うのがメタモルフィックテスティングということになります。
ここからはメタモルフィックテスティングに関する当社の取り組み事例を紹介します。
当社事例~自然言語処理に対するメタモルフィックテスティング
1つ目は、自然言語処理のモデルに対するメタモルフィックテスティングの適用です。
昨今では ChatGPT や LLM の流行によって、自然言語処理の AI モデルに対する品質保証の議論が盛んに行われるようになりました。
例えば、複数のテキスト間の類似度判断、あるいはテキストの要約・分類、さらに翻訳といったタスクに対し、メタモルフィックテスティングが有用かどうかといった研究もすでに行われています。
また、自然言語処理におけるメタモルフィック関係の一例を以下にまとめました。
| NLPタスク | メタモルフィック関係の例 |
|---|---|
| テキスト類似度 | 同一プロパティ単語の置換、類義語置換、センテンス入れ替え |
| テキスト要約 | 同一プロパティ単語の置換、類義語置換、センテンス入れ替え |
| テキスト分類 | 類義語置換、一部単語のマスク、省略ごとの置換 |
| 翻訳 | 単語置換で文構造が不変 |
当社でも自然言語処理(テキスト要約のモデル)に対し、メタモルフィック関係の有用性について、「要約」のモデルを基に評価実験を行っています。その結果、以下のように現状では良い結果は出ていません。3つのメタモルフィック関係の定義については、いずれも精度が低くなっています。
| メタモルフィック関係 | 精度 |
|---|---|
| 同一プロパティ単語の置換 | 29.03% |
| 類義語置換 | 0.1% |
| センテンス入れ替え | 47.28% |
基本的に人の解釈に大きく左右される自然言語を機械的に判断することは困難と言えます。一方で、倫理や公平性といった比較的客観的な基準が作れるようなテキストであれば、メタモルフィックテスティングが作りやすくなる可能性はあると考えます。いずれにしても自然言語処理モデルにおけるテスト手段の研究は今後も重要な課題となります。
当社事例~データ処理に対するメタモルフィックテスティング
2つ目は時系列データを処理するモデルに対して「モデル」と「学習プログラム」、それぞれに対する2種類のメタモルフィックテスティングを組み込んだ取り組みです(図表9)。
月ごとに学習データを使ってモデルを作るプロセス(図表9左側の破線)があり、これに対してメタモルフィックテスティングを組み込んでパイプラインを作っています。
また、途中で仕様変更があった場合などに、その学習プログラムの変更に対して走るパイプライン(図中央部の破線)にメタモルフィックテスティングを適用した事例になっています。ある意味、MLOps※的なものと考えられます。
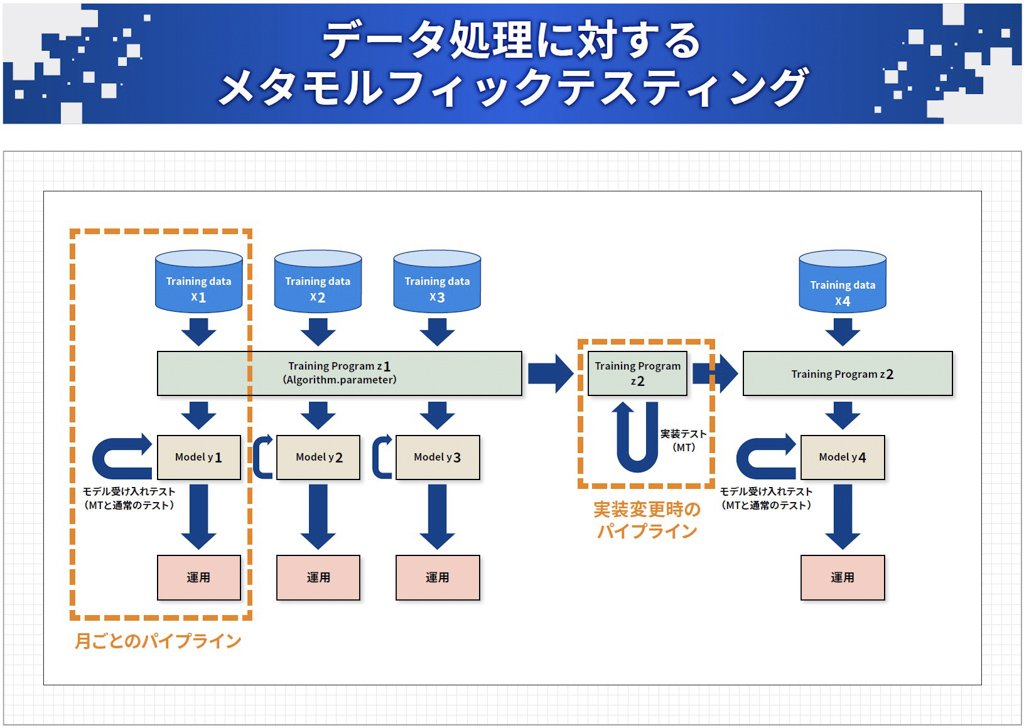
図表9:2つの種類のメタモルフィックテスティングを両方組み込む取り組みを行った
※MLOpsとは、機械学習(Machine Learning)と、運用(Operations)を組み合わせた造語で、機械学習モデルのライフサイクル全体を効率的に管理するための実践や手法を指します。
■データ増幅
最後は「データ増幅」の取り組みです。
対象としたのは、画像の異常検知を行うAIモデルです。基本的には正しい画像を学んで、そこから外れたもの(異常がある画像)を探すというモデルです。一般的に画像系のAIモデルを作るには多数の学習データが必要になりますが、ここで課題となったのは「正しいデータ(画像)はたくさんあるが、異常なデータ(画像)が少ない」ということでした。異常な画像がないとテストができません。そこで、少ないデータの中から異常のデータを多数作っていくというアプローチを検討しました。
このプロジェクトにおいては、少ないデータから学習ができる「SinGAN」という技術を採用してモデルを作りました。
例えば、ここに無数の鳥が群れで飛んでいる画像があります(図表10)が、「SinGAN」では、この1枚の画像から学習を行い、似たような画像をたくさん作り出すことができます。具体的には、1枚の画像を細かく切っていき、それらを多数の画像として学習させるというアプローチになっています。

出典:SinGAN: Learning a Generative Model from a Single Natural ImageICCV 2019Tamar Rott Shaham, Tali Dekel, Tomer Michaeli
図表10:1枚の画像データから似たような画像を多数生成し、異常データとして学習させる
これにより少ない異常データを学習し、似たような異常データを多数作成することが可能になりました。また「SinGAN」では、複数の異常データを混ぜて学習し、さまざまな異常データをランダムに生成することができます。つまり、1つの異常データから似たものだけを作るのではなく、さまざまな異常がミックスされた画像を生成でき、これを使って、「すでに起きている異常」のバリエーションをテストできるようになっています。
これは、画像認識AIのテストに生成AIを活用した事例ということができると思います。
おわりに
AI品質保証に対する当社の取り組みを紹介してきましたが、現状は研究が縦割りになっている面もあり、あらゆるAIプロダクトの品質保証を全面的にサポートする段階に達していません。今後も、社会動向、最新研究、調査を踏まえて、皆様のご要望にお応えできるAIプロダクトの品質保証システムづくりを進めていきます。
この記事をシェアする