ナレッジ
AI技術「RAG」とは?仕組みや生成AIとの関係など分かりやすく解説

目次
生成AIがビジネスの現場に広がる中、「RAG(検索拡張生成)」という言葉を耳にする機会が増えてきました。
ChatGPTなどの大規模言語モデル(LLM)は強力な生成能力を持つ一方で、「最新情報に弱い」「社内データを参照できない」といった課題も抱えています。こうした限界を補い、業務知識を生かした高精度なAI応答を可能にするのがRAGです。
この記事では、RAGの仕組みや従来の生成AIとの違い、導入メリット・実装手順・代表的なツールや企業事例、そして「RAGエージェント」への発展形まで、分かりやすく整理して解説します。
社内ナレッジの有効活用や、FAQ・サポート業務の効率化を検討している方は、ぜひ導入の第一歩としてお役立てください。
AI技術としてのRAG(検索拡張生成)とは
本章では、RAGの基本的な定義や仕組み、通常の生成AIとの違いについて解説します。
RAGの読み方・意味・略称
RAGは「ラグ」と読みます。
正式には「Retrieval-Augmented Generation」の略称で、検索(Retrieval)と生成(Generation)という二つの要素を組み合わせた技術を意味します。日本語では、検索拡張生成と表現されます。
RAGの最大の特徴は、生成AIが回答を出す前に外部の情報源から関連情報を検索し、検索して得られた情報をベースに文章を生成する点にあります。これにより、業務に特化した知識や特定の組織や社内のドキュメントを反映した回答が可能となり、精度や信頼性が大きく向上します。
通常の生成AIとの違い
ChatGPTやGemini、Claudeなどの生成AI(Generative AI)は、膨大なテキストデータを基に事前学習をしており、自然な文章生成が得意です。
しかし、生成AIには以下のような課題がありました。
- 学習データが固定されているため、最新の情報や固有業務に対応できない
- 事実と異なる回答(ハルシネーション)が出やすい
- 特定企業や業界向けのカスタマイズが難しい
RAGはこうした課題を解決するために開発された技術です。
生成AIが質問を受けると、RAGはまず関連情報をベクトル検索などで抽出し、その検索結果をプロンプトに追加した上で回答を生成します。つまり、RAGは「生成前に検索する」ことで、「文脈に即した」「根拠に基づいた」高精度な応答を実現する仕組みと言えます。
例えば、自社製品のマニュアルや社内ナレッジベースをRAGに組み込むとします。
すると、カスタマーサポートや社内FAQ対応などの現場で実用的な回答の素早い提供が可能になるのです。
RAGの仕組みとアーキテクチャ
RAGの核となる仕組みは、「検索した情報」を踏まえて「文章を生成する」という二段構えの構造です。
ここでは、RAGの全体的な構成、検索と生成の連携、そして検索の要となる「ベクトルデータベース」と「チャンク処理」について解説します。
基本構造
RAGは大きく分けて、「検索パート(Retrieval)」と「生成パート(Generation)」という二つの処理ステップから構成されています。
- ユーザーが質問を入力すると、その内容を基に検索クエリを生成します。
- 生成されたクエリを基に、AIはベクトルデータベースから関連する情報(チャンク)を検索します。
- 得られた検索結果が、生成AI(例えばGPT-4など)にプロンプトとして渡され、最終的な回答が生成されます。
この流れにより、RAGは従来のLLMでは参照できなかった特定の組織で固有の知識や最新情報を取り込んだ応答を実現します。
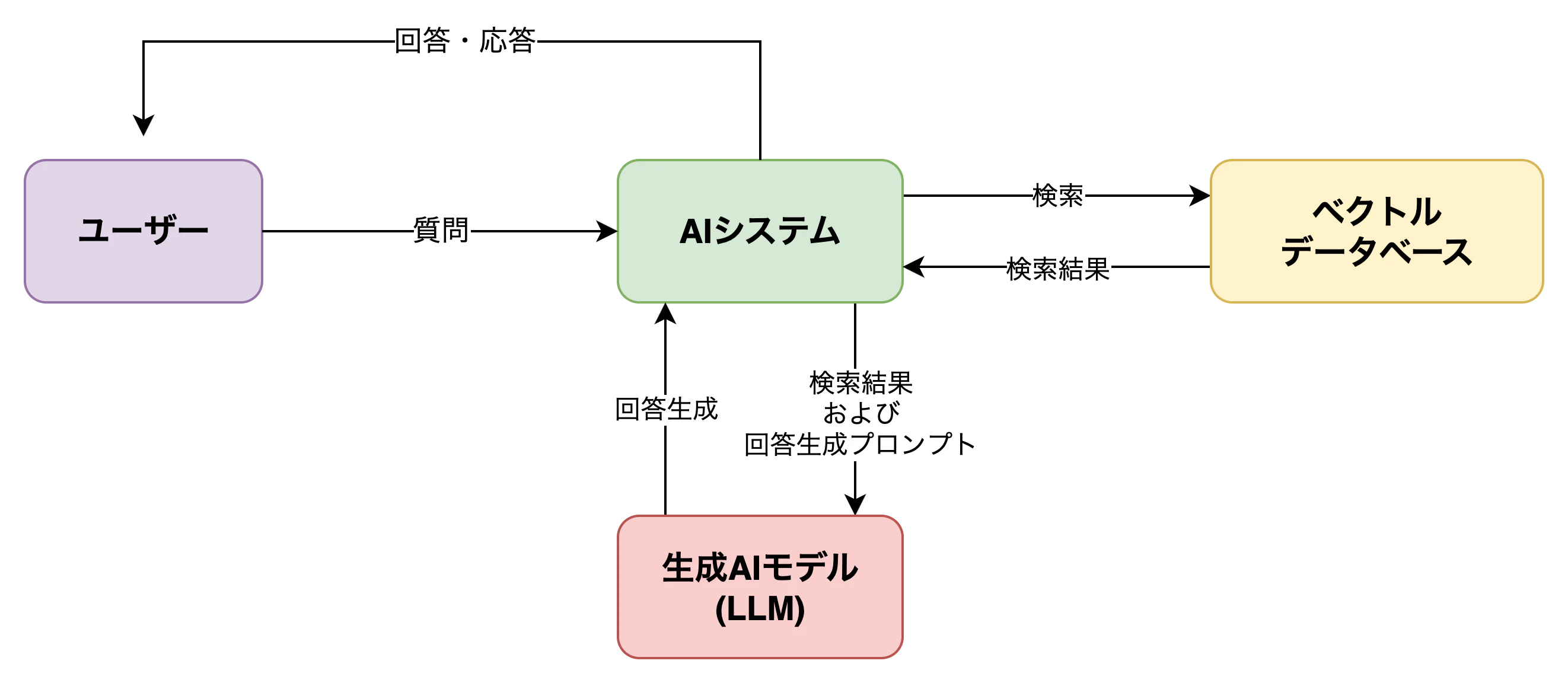
検索(Retrieval)と生成(Generation)の連携
RAGにおいて、検索と生成は密接に連動しています。
まず、事前準備として、社内文書やFAQをベクトルDBに格納する。というのを入れた方が良いと思います。その際にエンベディングモデルを使用して社内文書やFAQをベクトル変換します。
次に、ユーザーの質問を数値ベクトル(特徴量)に変換します。これを基に、ベクトルデータベース内にある膨大な社内文書やFAQのベクトルと照合し、最も関連性の高い情報チャンク(=文書の一部)を抽出します。
次に、抽出されたチャンクが生成AI(LLM)へのプロンプトとして渡されます。
生成AIは、質問とその文脈情報(=検索結果)を踏まえて、より正確で業務に即した回答を出力できるようになります。
このように、検索と生成をうまく組み合わせることで、ただの会話ではなく根拠に基づく会話が実現されるのです。
ベクトルデータベースやチャンク処理
RAGの情報検索の要となるのが「ベクトルデータベース」と呼ばれる仕組みです。
これは、テキストを意味的に数値化(ベクトル化)して保存し、ユーザーの質問との「意味の近さ」に基づいて高速検索を行うデータベースです。
ベクトルデータベースの代表例には、以下のような製品やサービスがあります。
製品・サービス | 概要 |
|---|---|
Pinecone | クラウド特化型ベクトルDB |
Weaviate | オープンソース、拡張性・高速性あり |
ChromaDB | オープンソース |
FAISS | Meta開発の高速ベクトル検索ライブラリ |
Azure Cognitive Search | Azureクラウド統合、多言語・セキュリティ対応 |
図表2:RAGに用いられる主なベクトルデータベース
RAGのメリットとデメリット
RAGの導入を考える上で欠かせないポイントとして、従来の生成AIやFAQボットと比べたメリットとデメリットについて整理しましょう。
メリット
- 「自社固有」「業務固有」の知識を用いてAIが回答できるため、ビジネスで本当に使える高精度な応答が可能
LLMによる事実無根の情報(ハルシネーション)が少なくなり、出典付き回答や根拠提示も実現しやすくなる
- AIモデル自体の再学習やファインチューニングが不要で、文書データの差し替えやアップデートで即時対応可能
- コンプライアンスや機密情報管理などのガバナンス要求にも、ローカル環境・クラウド環境両方で対応可能
デメリット
- 「検索」部分の精度や設計が甘いと的外れな情報が抽出され、全体の出力品質が悪くなるリスクがある
- 社内文書等の整理・チャンク化・ベクトル化に一定の初期工数と専門知識が必要
- 情報量が膨大になるとベクトルデータベースのコスト増・検索速度低下が課題となる
- 生成した出力内容や根拠筒抜け情報の監査・ログ取得、著作権管理、MLOps観点の運用フロー整備が不可欠
- 普通のチャットボット以上に、「プロンプト設計」「検索クエリ最適化」「文書構造設計」などのノウハウが必要
参考:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
RAGはどう作る?開発・実装に必要な技術とツール
RAGの導入には、データ準備から検索エンジン、生成AIとの連携まで複数のステップがありますが、全てを一から自作する必要はありません。最近では、主要クラウドベンダーやオープンソースコミュニティから多くの支援ツールやフレームワークが提供されています。
この章では、RAGシステムを構築するための全体フローと、具体的な技術とツールを分かりやすく解説します。
1. 知識データの収集・整備 | 社内マニュアルや商品仕様書など、AIが参照すべき文書資料を収集し、クレンジング・整理します。 |
|---|---|
2. テキストのチャンク化 | 大量のテキストを「チャンク」(段落または意味的なまとまり)へ分割します。これにより検索効率が大幅に向上します。 |
3. ベクトル化 | 専用のベクトルエンコーダ(例:OpenAI APIのtext-embedding-ada-002モデルなど)でチャンクごとにベクトルを生成します。 |
4. ベクトルデータベースへの格納 | 生成されたベクトルを各種データベース(PineconeやChromaDB、Azure Cognitive Searchなど)へ格納します。 |
5. 検索と生成の連携設計 | ユーザーの質問を受けて検索 → 検索結果をプロンプトに挿入 → LLMが回答を生成、という一連の流れをプログラムで構築します。 |
6. LLM(生成AI)との接続 | OpenAI API(GPT-4)や Azure OpenAI Service、Claude などと連携して、回答生成機能を組み込みます。 |
7. アプリケーション化 | API形式で自社の業務システムやチャットボットに組み込むことで問い合わせ窓口・FAQ・ヘルプデスクへの応用が実現します。 |
図表3:RAGを構築するステップ
また、RAGの構築には、以下のようなツールやサービスがよく使われています。
ツール・サービス | 概要 / 主な特徴 |
|---|---|
LangChain | Pythonライブラリ、RAG構築の定番。マルチクラウド、複数DB対応 |
LlamaIndex | データ連携重視、文書管理機能が豊富 |
Vertex AI RAG Engine | Google Cloud原生サービス、スケーラビリティ大、高セキュリティ |
Azure Cognitive Search | Microsoft Azure組込みのフルマネージド検索サービス |
Pinecone | 高可用性クラウド型ベクトルDB |
図表4:代表的なRAG開発・運用ツール
上記のツールやサービスを使うことにより、ベクトル化・検索・生成のそれぞれのプロセスを簡潔に構築できます。PoC(概念実証)から本番運用までのスムーズな移行をサポートしてくれます。
【事例】企業でのRAG導入・活用
RAGは、社内ナレッジや業務データを活用できるAI技術として、国内外で導入が進んでいます。ここでは、国内外の実践的な活用例を紹介します。
海外先進事例
米国の金融機関Morgan Stanleyは、社内ナレッジベースにRAGを活用し、2,000件以上の既存FAQや文書から専門的回答を即時生成するシステムを構築しました 。
RAGの導入により、従来は検索に10分以上かかっていた業務知識が数秒で取得可能となり、社内ヘルプデスク工数も約半減したと報告されています。
国内企業の動向
リコーは、社内文書を活用できるRAG型チャットボットを構築し、営業提案や申請対応、報告書作成などの業務を効率化したとのことです。
ドキュメントをアップロードするだけで運用でき、根拠提示やハルシネーション抑制にも対応。複数プランを通じて社内ナレッジ活用の高度化を推進されています。
RAGエージェントとは
近年ではRAGを単なる拡張検索から一歩進めて、「RAGエージェント(RAG Agent)」という自律的なAIエージェントの構築の動きが活発になってきています。
RAGエージェントは、次のような特徴があります。
- 社内や自治体の膨大なドキュメントを自動学習します。必要に応じて追加調査や再検索も行いながら、ユーザー問い合わせの流れ全体のハンドリングが可能です
- 単なるQ&A応答だけでなく、業務ワークフローの自動化(例:顧客対応→必要手続き案内→クリエイティブ提案 など)まで担う高度なエージェント型AIが実現されています
- 開発フレームワークとしてはLangChain Agents、Vertex AI Search + RAG、MicrosoftのCopilotスタジオなどが利用可能です
今後のAI導入は、「回答するAI」から「動いて支援するAI」へと進化していくと考えられています。
RAGとAIの展望、導入に向けて
RAGは、従来の生成AIでは難しかった業務固有の知識や最新情報の反映を可能にする技術として、企業のDX推進において重要な役割を果たしつつあります。
チャンク処理やベクトル検索の技術、LangChainなどの開発フレームワークの進化、そしてエージェント型への展開。RAGは、現場業務の自動化・高度化に大きな可能性をもたらしています。
ただし、その導入に当たっては、以下のような準備や配慮が不可欠です。
- 文書構造や情報資産の整備
- ベクトルDBの選定と運用
- プロンプト設計や再検索制御の最適化
- AI倫理・情報セキュリティ・ログ管理への対応
RAGは決して万能な技術ではありませんが、目的や課題に応じて適切に設計・運用することで、実用性と信頼性を両立できる手段となります。
今後は、企業ごとのニーズに応じたRAGのカスタマイズや、エージェント型AIとの組み合わせによる業務プロセス革新が進むと見込まれています。
この記事を書いた人

執筆
HQW!編集部
この記事は面白かったですか?
今後の改善の参考にさせていただきます!















































-portrait.webp)





























