スキルアップ
LLMはシステムテストでどこまで使えるのか? ~LLMを使ったテスト分析・テスト設計能力を測定する手法のご紹介~

目次
近年、LLM(大規模言語モデル)は目覚ましい進化を遂げ、その性能も日々向上しています。各種ベンチマークで人を超える結果を出し、業務利用も活発化しています。こうした中、「ソフトウェアテストの現場でもLLMを活用できるのではないか」と考える方は多いのではないでしょうか。
では、LLMは主に要件の妥当性確認を行うテストレベルであるシステムテストにおけるテスト分析やテスト設計で、実際にどこまで使えるのでしょうか。
ベリサーブの研究開発部では、この問いに対してLLMによるシステムテストの能力を定量的に測定するベンチマーク手法の研究に取り組みました。その結果、LLMは「テスト観点を抽出する力」は一定程度ある一方で、「漏れなく抽出すること」や「組み合わせて構造化する力」には課題があることが見えてきました。本記事では、システムテストにおけるLLMの能力を測るためのベンチマーク手法と、そこから得られた知見や現時点でのLLMの活用方法を紹介します。
なお、本記事はJaSST‘26 Tokyo*1での発表を基に再構成したものです。
LLMの進化とシステムテストでの活用の期待
LLMの進化は、人間中心のAI研究を推進するスタンフォード大学の研究機関が出しているAI Index Report*2にてLLMの能力が示されています。次の図表1が示す通り、知識・言語理解や競技数学レベルの数理推論能力、画像から物体・シーンのカテゴリを識別する能力など、あらゆるベンチマークで高い性能であることが見て取れます。
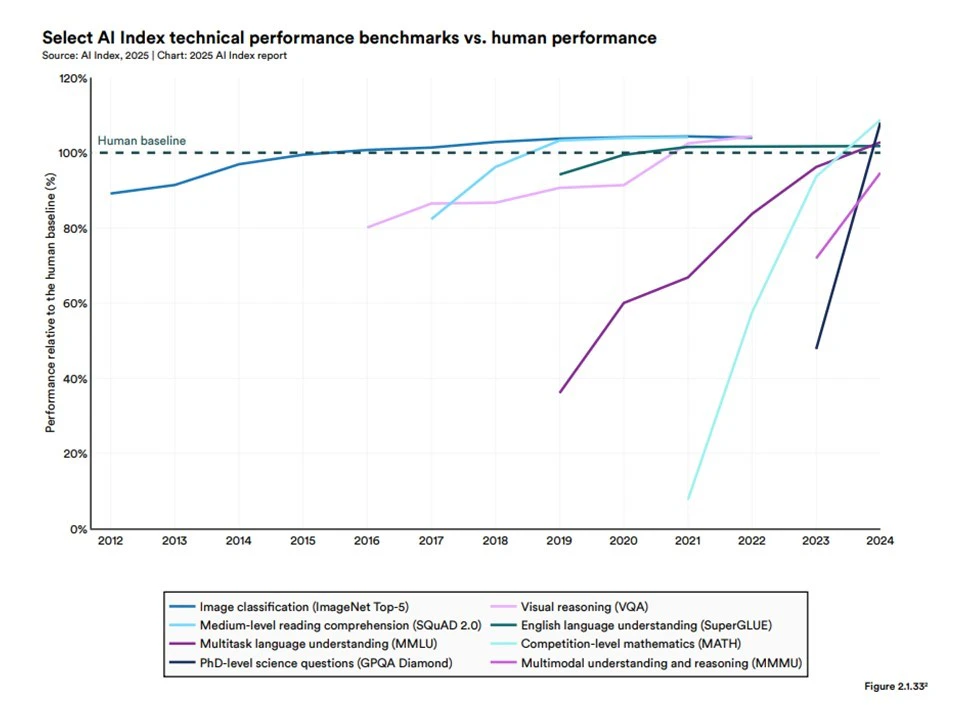
こうした中、システムにおけるテスト分析やテスト設計にもLLMを活用できるのではないか、という期待が高まっています(図表2)。
ソフトウェアテスト分野におけるこれまでの研究では、主にユニットテストにおいて生成されたテストコードに対して、その網羅性やミューテーションスコア*4、そして欠陥の再現性などを識別する能力といったものを指標とする測定が行われてきました。
一方で、システムテストにおける自然言語を中心としたテスト分析やテスト設計能力を測定する枠組みは十分に整備されていません。
そこで本研究は、LLMのシステムテストにおけるテスト分析やテスト設計能力がどの程度なのかを、定量的かつ継続的に測定することを目的に進めています。
本研究で測った三つの能力
まず、テスト分析やテスト設計の能力を何で測るかということが重要になります。テスト分析やテスト設計は、ソフトウェアテストの資格認定団体であるISTQB*5が発行するシラバスやソフトウェアテストの国際標準であるISO/IEC/IEEE29119*6などで基本的な考え方が示されています。その一方で、成果物の構成や粒度に対して統一した決まりがなく、LLMに出力させた場合にも構成や粒度にばらつきが生じます。そのため出力したままでは単純な比較が難しくなります。そこで本研究では、テスト分析やテスト設計の能力を比較しやすいように次の三つの能力で測ることとしました。
- テスト分析やテスト設計の入力となるテストベースから単一のテスト観点として「何をテストするか」を導出する力(テスト観点導出力(単一))
- そのテスト観点を組み合わせて構造化する力(テスト観点導出力(組み合わせ))
- 組み合わせたテスト観点から欠陥を識別できるようにテストケースとして構成する力(欠陥識別力)
正解がないテストをどのように測定するか
テストの原則*5からも分かる通り、システムテストでは正解を一意に定めることができないケースがあります。そのような場合、テストによりテスト対象の振る舞いが有効か無効かを判定するための正解をどのように定義するのかが課題の一つでした。人が正解セットを作ったとしてもそれが唯一の解にはならないからです。このため、LLMが出力したものが正解セットになくとも、有効と判断できるものがあり得ます。これを有効ではないと判断してしまうとLLMの能力を過小評価することにつながります。そこで本研究では、出力を二値分類で判定し、混同行列を用いて測定することとしました。さらに「正解セットに含まれていなくても、有効と判断できるものは正として扱う」こととしました。
具体的には図表3の通り、正解セットにない場合も有効であればTP(正であるものを正しく正と判定)として判定する、というものです。
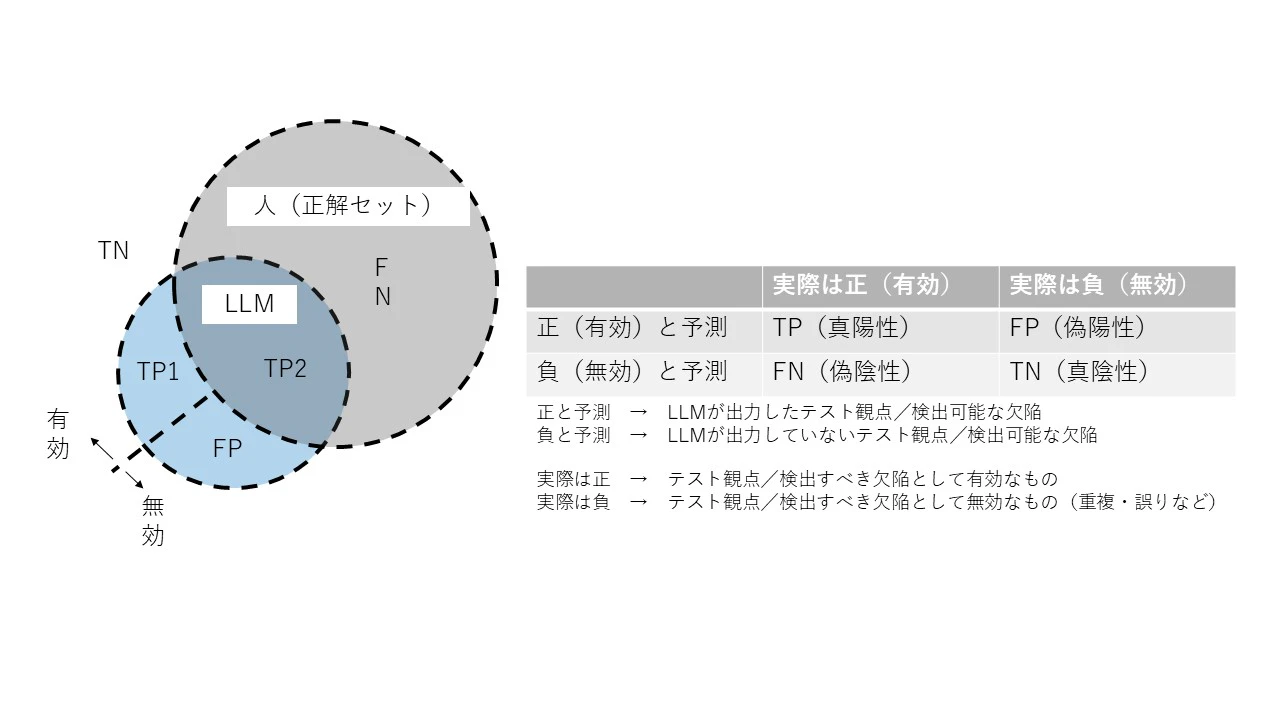
これにより、あらかじめ用意した正解セットと一致しているものだけでなく、実際に有効であるものを踏まえた測定が可能となります。それぞれの指標は、次の図表4の通りとなります。

以上の考え方に基づき、本研究ではテスト分析・テスト設計の能力を「テスト観点導出力(単一)」「テスト観点導出力(組み合わせ)」「欠陥識別力」の三つに分け、それぞれに混同行列を用いて定量的に測定する方法を、ベンチマーク手法として提案しています。
検証方法
検証対象としては二つのWebアプリケーションを用いました。一つは、操作マニュアルをテストベースとしたテスト管理ツールです。機能は「テストスイートを作成する機能」と「テストスイートを設定する機能」の二つに限定しました。もう一つは、設計書をテストベースとした社員情報検索システムです。こちらは機能を「キーワード検索機能」に限定しました。
LLMの対象としたモデルは検証当時、利用可能だった以下のモデルを使用しました。
- GPT-5
- GPT-5.1
- GPT-5.1 Thinking
- GPT-5.1 Pro
またLLMのモデルそのものの能力を見極めるためにプロンプトは複雑にせず、ロール指定とテストケース作成の指示を中心としたシンプルな構成としました(図表5)。

測定の流れは以下の通りです。
- テストベースからLLMにテストケースを生成させる
- 生成されたテストケースから人によってテスト観点(単一・組み合わせ)や検出可能な欠陥を導出する
- 各出力に対して事前に用意した正解セットと比較し、TP/FP/FN/TNを人によって判定する
- TP/FP/FN/TNを整理し、指標を算出する
検証結果が示した「当たるが、漏れる」
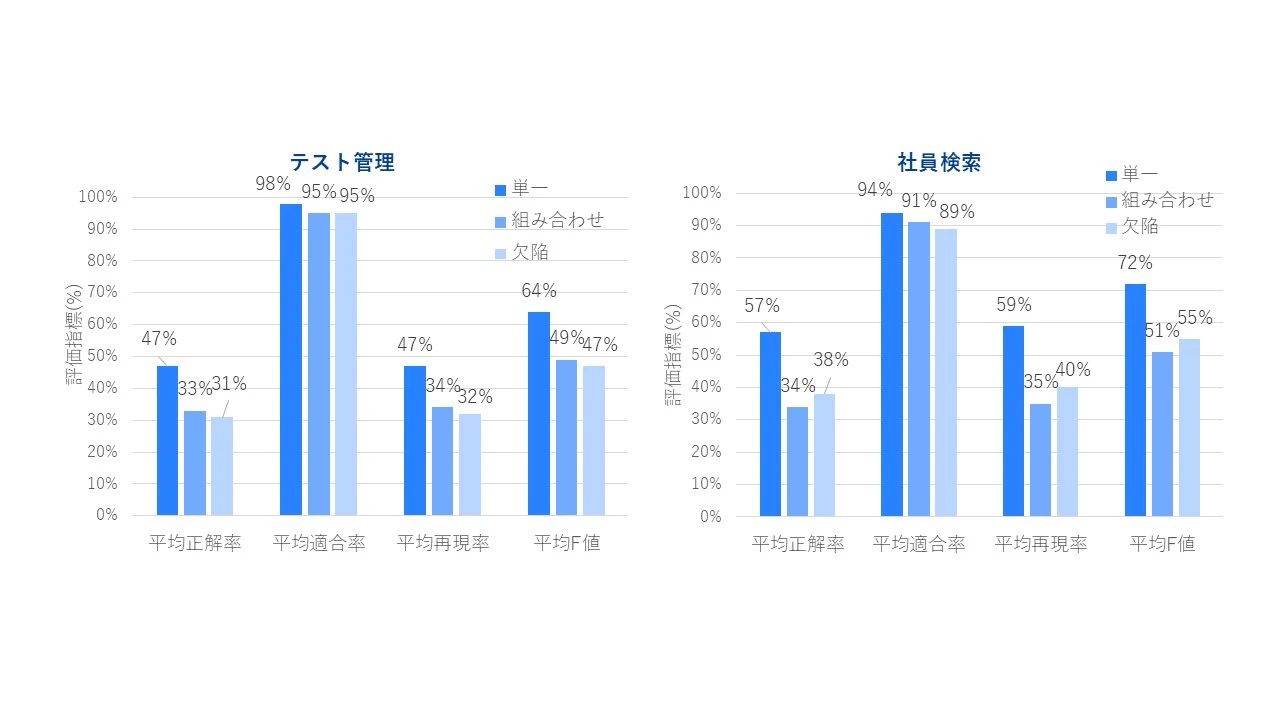
検証結果を端的にいうと、LLMは「当たるが、漏れる」でした。図表6が示すように、適合率は各モデルで89~98%と高く、これにより出力したものが高い確率で有効であったことが分かります。一方、正解率や再現率は31~59%にとどまりました。これは有効なテスト観点や検出可能な欠陥を一定程度出せている一方、拾い切れていないものも少なくないと考えられます。
また、単一のテスト観点の導出における正解率や再現率(47~59%)は組み合わせや欠陥識別の正解率、再現率(31~40%)よりもやや高い傾向が見られました。この結果から、構造化するよりもテストベースから必要な要素を抽出し、列挙することが比較的得意であろうと推察できます。ただし、抽出し列挙するものの、人の能力に達しているとは言えない数値であるとも言えます。※LLMのモデル間の差異がなかったため各モデルの平均値で出しています。
得られた知見 ~LLMをどのように活用すればいいのか
今回の結果から、システムテストにおける現実的なLLMの活用方法として主に二つの使い方ができるという知見を得ました。
一つ目は、テスト分析のたたき台として使う方法です。LLMの出力は、網羅性に課題はあるものの、内容の妥当性は高いことが分かりました。そのため、まずはLLMにテスト観点やテストケースを出力させ、それを人がレビューしながら補強していく使い方が有効となります。テスト観点を組み合わせるための構造化や、テストケースの作成を人が主導することにより精度や網羅性を確保するようにします。
二つ目は、人が作った作成物の漏れを補う使い方です。検証結果では示していなかったのですが、正解セットにはなくLLMが出力したもので有効と判定するTP1の割合は平均すると40%、一部の条件では60%前後となる場合がありました。この結果から、人では見つけにくい要素をLLMが出力できることを示しており、人が作成したテスト観点やテストケースを補完する手段として活用できると考えられます。
今後の課題
現状、テスト観点の導出や検出可能な欠陥の導出、有効無効の判定は人が行っているためモデルが出るたびにすぐ計測できません。今後はこの導出や判定を自動化し、新しいモデルが出るたびに迅速に計測できるように研究を進めたいと考えています。また、正解セットに対する課題として、社内の有識者レビューからテストケースの過不足に関する指摘を受けています。正解セットを見直した結果次第では、測定した結果の解釈にも影響を及ぼす可能性があるため、今後は正解セットの改善にも取り組んでいく予定です。
まとめ
現状のLLMにおけるテスト分析・テスト設計の能力が分かると共に、今後も継続して計測できる枠組みとして、ベンチマーク手法を作ることができました。
今回の結果から見えてきたことは、LLMは有効なテスト観点を出力する一方で、網羅性や構造化には課題があるということです。このことから現時点では人の代替として使うよりも、テスト分析やテスト設計のたたき台として活用する、人の作成物を補足する形で活用するのが現実的だと考えています。
ベリサーブの研究開発部では、今後も自動計測の仕組みや正解セットの改善を進めながらシステムテストにおけるLLM活用の実態をより客観的に捉えられるようにし、その結果をJaSSTのような機会を用いて発表できればと思います。
参考
* 1: JaSST(ジャスト)は、NPO法人ASTER (ソフトウェアテスト技術振興協会)が運営するソフトウェア業界全体のテスト技術力の向上と普及を目指すソフトウェアテストシンポジウム ※JaSST:Japan Symposium on Software Testing。中でも東京開催は各地域の中で最大規模となるシンポジウム https://jasst.jp/tokyo/26-about/
*2:Stanford HAI, Artificial Intelligence Index Report 2025, Chapter 2: Technical Performance, Fig. 2.1.33, p.13.(PDF: < https://hai.stanford.edu/assets/files/hai_ai-index-report-2025_chapter2_final.pdf >) ※ライセンス:CC BY-NC-ND 4.0
*3: Stanford HAI, Artificial Intelligence Index Report 2025, Chapter 2: Technical Performance, Fig. 2.1.33, p.13.(PDF: < https://hai.stanford.edu/assets/files/hai_ai-index-report-2025_chapter2_final.pdf >) ※ライセンス:CC BY-NC-ND 4.0
*4:ミューテーションスコアは、ソースコードに意図的なエラーを挿入し、既存のテストがそれをどれだけ検出できたかを示す割合
*5:ISTQBテスト技術者資格制度 Foundation Level シラバス 日本語版 Version 2023V4.0.J02。ここにテストの原則について記載
*6:ISO/IEC/IEEE 29119とは、さまざまな組織がさまざまな種類のソフトウェアテストを行う際に利用可能な、国際的に合意されたソフトウェアテストの規格
この記事を書いた人

執筆
吉川努
株式会社ベリサーブ 研究開発部。2006年にベリサーブに入社。組み込み製品を中心に車載、エンタープライズ、Web・スマホアプリなど多岐にわたってソフトウェアテスト・QA業務を従事しながらテスト設計改善の方法論などを研究。現在は研究開発部にてリスクベースドテストやモデルベースドテスト技術の開発に取り組む。
この記事は面白かったですか?
今後の改善の参考にさせていただきます!































































-portrait.webp)


























