Technical Information
次世代を創る、AIの原動力:生成AIの進化とNVIDIAの挑戦

生成AIの登場は、さまざまな分野に大きな変革をもたらしています。ある調査では生成AIが世界経済の生産性に与える影響は年間で最大4.4兆ドルに達するという試算が出ており、これは2024年の日本の国内総生産(GDP)である4.3兆ドルを超える規模となっています。本講演では、さらなる進化を続ける生成AIの動向と、それに対するエヌビディア合同会社(以下、NVIDIA)の取り組みについてお話しします。
※この記事は、2025年10月に開催した『ベリサーブ モビリティ イニシアティブ 2025』の講演を基にした内容です。

エヌビディア合同会社
エンタープライズ事業本部
事業本部長
一般社団法人
日本ディープラーニング協会
理事
井﨑 武士 氏
NVIDIAのプラットフォーム戦略
昨今のメディアによる報道の影響もあり、NVIDIAに対しては半導体メーカーだというイメージが強いかと思います。ただ、実際には4万人弱の全従業員のうち半数以上をソフトウェアエンジニアが占めていて、ハードウェアだけでなく、それを有効活用するためのソフトウェアへ大きな投資をしています。われわれが目指すのは「Accelerated Computing Platform Company」、つまり高速なコンピューティングによって社会課題を解決するプラットフォームを提供する企業であることです。NVIDIAが推進するプラットフォーム戦略は、以下の三つの要素で構成しています。
■アクセラレーテッドコンピューティングインフラ
ハードウェア製品の主力はご存じの通りGPUですが、これ以外にもArmベースのCPUや、メインCPUから独立してデータ処理が行えるDPU(Data Processing Unit)を搭載したSmartNIC(スマート・ネットワーク・インターフェースカード)も製品としてラインアップしています。
GPU・CPU・DPUという三つのプロセッサを擁することには狙いがあります。GPUは計算処理のソースとなるデータを外部のストレージやネットワーク経由で取得しますが、その際にデータはいったんCPU側のメモリに読み込まれます。その後、これをGPU側のメモリにコピーして処理を行うというプロセスになるので、CPUとGPU間の通信帯域が狭いと遅延が発生します。そのため、一般的なPCI Expressではなく、CPUとGPU間で900GB/sという超高速通信を実現するNVLinkという独自技術を開発しています。さらに、最近のLLMはモデルが巨大化しているため、複数ノードでの分散処理が主流となっています。このノード間の通信を低遅延・広帯域で接続するために、DPUを搭載したネットワーク製品を提供しています。
■ソフトウェアライブラリ
NVIDIAのハイエンドGPU製品にはコア数が2万を超えるものもあります。これを最大限に活かす並列コンピューティングの開発プラットフォームとして提供しているのがCUDA(Compute Unified Device Architecture)で、その中でもニーズが高いと思われるタスクをあらかじめライブラリ化して簡単に利用できるようにしています。例えば、行列演算やディープラーニング用のcuDNN(CUDA Deep Neural Network library)の他、最近では量子コンピューティングを加速するための状態ベクトルやテンソル演算を高速化するライブラリなども提供しています。
■アプリケーションフレームワーク
医療や自動運転など、特定の用途や業界に特化したアプリケーションの開発をサポートする多数のフレームワークを提供しています。AIやHPC(High Performance Computing)、3D環境など、それぞれのアプリケーション内で必要となる機能を効率良く開発するためのツールチェーンもしくはベースモデルを用意しています。
このように、NVIDIAが展開するプラットフォーム戦略は、ハードウェアからミドルレイヤーのソフトウェアまでフルスタックで構成されているのが大きな特徴です。これにより、世界中の数百万人に及ぶ開発者や2万社を超えるスタートアップ企業を支援する巨大なエコシステムを構築しています。
生成AIのためのNVIDIA AI Enterprise
NVIDIA AI Enterpriseは組織が生成AIを簡単かつ迅速に導入・運用するための包括的なソフトウェアスイートで、以下の三つのレイヤーによって構成されます。
NVIDIA NeMo
NVIDIA NeMoは企業向け生成AIアプリケーションの構築をサポートするフレームワークで、LLMの開発からデプロイに至る一連の作業に対応した以下のような機能で構成されます。
・NeMo Curator – キュレーション
生成AIの構築に必要なデータの収集や選別、整理を行う作業をキュレーションと呼びますが、これをGPUによって高速に処理するためのサービスです。
・Megatron Core – 分散学習
LLMの学習を複数のGPUサーバーに分散して実行するためのフレームワークです。
・NeMo Aligner – カスタマイズ
追加学習やファインチューニングなど、モデルのカスタマイズに役立つさまざまなスクリプトを提供しています。
・Triton & TensorRT-LLM – 推論の高速化
LLMの推論性能を最適化し、高速処理を可能にするためのソフトウェアライブラリです。
・NeMo Retriever – RAG
企業ユースなどでニーズが高まっているRAG(Retrieval-Augmented Generation:外部のデータベースなどを参照しながら回答を生成する技術)の実行を支援するためのサービスです。
・NeMo Guardrails – ガードレール
不適切な質問および回答の拒絶など、LLMを適切に制御するガードレールを導入するためのツールキットです。
■NVIDIA NIM
NVIDIA NIM(NVIDIA Inference Microservices)は推論に特化したマイクロサービスで、一般的なコミュニティモデルもしくはNVIDIA独自のモデルをベースに、GPUで高速化した学習済み推論モデルをコンテナ化して提供します。NVIDIAのエンジニアによるチューニングが施されており、Llama3ベースのモデルでは最大で5倍のパフォーマンスを発揮します。スピーチ・映像・画像・バイオロジーなど特定の用途・分野別に最適化されたモデルが用意されているため、実際のビジネス環境へ迅速かつ容易に展開が可能です。
■NVIDIA Blueprints
NVIDIA Blueprints はさまざまなユースケースに合わせたNIMの組み合わせ構成例で、AIアプリケーションの迅速な構築を支援します(図表1)。例えば、デジタルヒューマンを作成する場合、ASR(Automated Speech Recognition)で音声を認識、次にLLM+RAGで回答を生成し、TTS(Text-to-Speech)で音声に変換して出力という処理が必要になりますが、こうしたプロセスを一連のNIMで構成するためのリファレンスを提供しています。
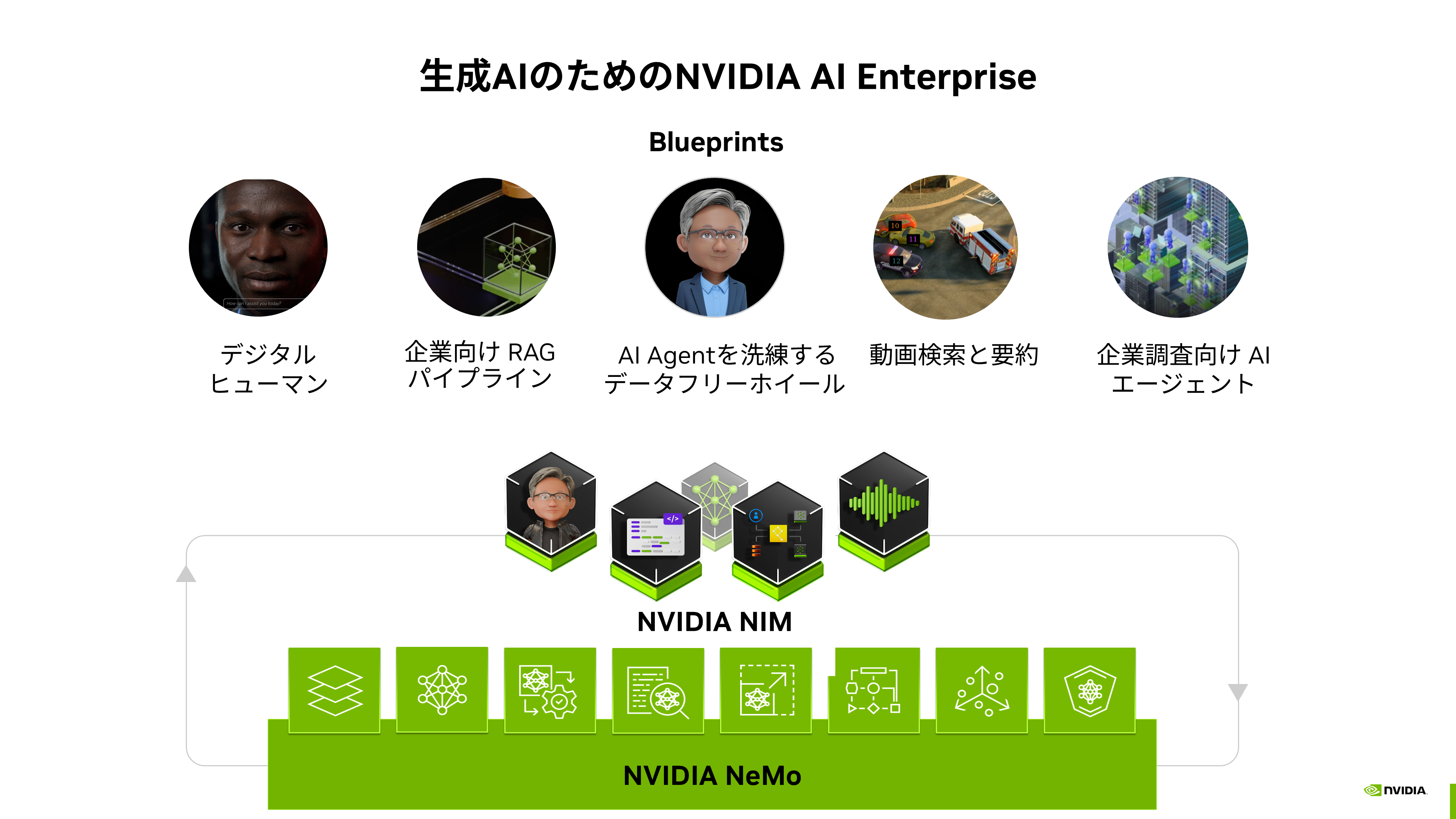
図表1:生成AIのためのNVIDIA AI Enterprise
■NVIDIA社内における活用例
NVIDIA AI Enterpriseで構築した生成AIアプリケーションは、われわれ社内でも実際に使用しています。「ChipNeMo」は名前の通りNeMoを活用したもので、GPUのハードウェア設計を効率化する生成AIです。GPU ASICのアーキテクチャに関するQ&Aに対応したチャットボット、不具合が発生した場合のバグの分析とレポート、設計に使用するEDA(Electronic Design Automation)という専用ツールを操作するためのスクリプトの自動生成などの機能を備えています。
Q&Aチャットボットでは、これまで10~45分かかっていた情報の収集が瞬時に完了するようになりました。また、レポートの要約やバグの迅速な解決によって、1件当たり平均で4分、全体で毎日約1,000時間分の工数が削減できています。さらに、コードの自動生成によって準備作業が数時間から数分に短縮されるなど、作業効率が劇的に向上しました。これにより、従来は2年に1回だったアーキテクチャの刷新が毎年1回のペースとなり、製品サイクルの大幅な短縮を実現しています。
AIの進化と未来
すでにご存じの方も多いと思いますが、生成AIに続くものとして「エージェントAI」が登場し、徐々に広がりを見せ始めています。さらにその先にはエージェントがエンボディ化(Embodied)を遂げて「フィジカルAI」が誕生する、これがNVIDIAの描くAIの未来像です。
■エージェントAIとは
エージェントAIはさまざまなアクションを自律的に行うAIで、2025年中には約半数の組織が導入に踏み出すといわれています。エージェントAIの活用によって製品の品質やサイクルタイムが約40%向上すると期待され、さらに2028年までには企業が使う業務用ソフトウェアの33%にはエージェントAIが組み込まれると予測されています。
エージェントAIの構成要素として最も重要なのは「リーズニングモデル」で、入力されたプロンプトを正しく細分化し、解釈した上で回答を生成します。これを実行するためにエージェントAIは検索システムや外部のデータベース、計算のためのコンピュータなど、さまざまなツールを使用します。また、メモリも非常に重要で、例えばスレッド内のロジックを一定に保つためには短期的な記憶、パーソナライゼーションの実現には長期的な記憶を保持するためのメモリが必要になります。さらに、エージェントは単独で動くだけでなく、他のエージェントとの連携も可能です。このように、さまざまなリソースを活用しながら自動的に目的の達成に向かっていく、これがエージェントAIの原理です(図表2)。
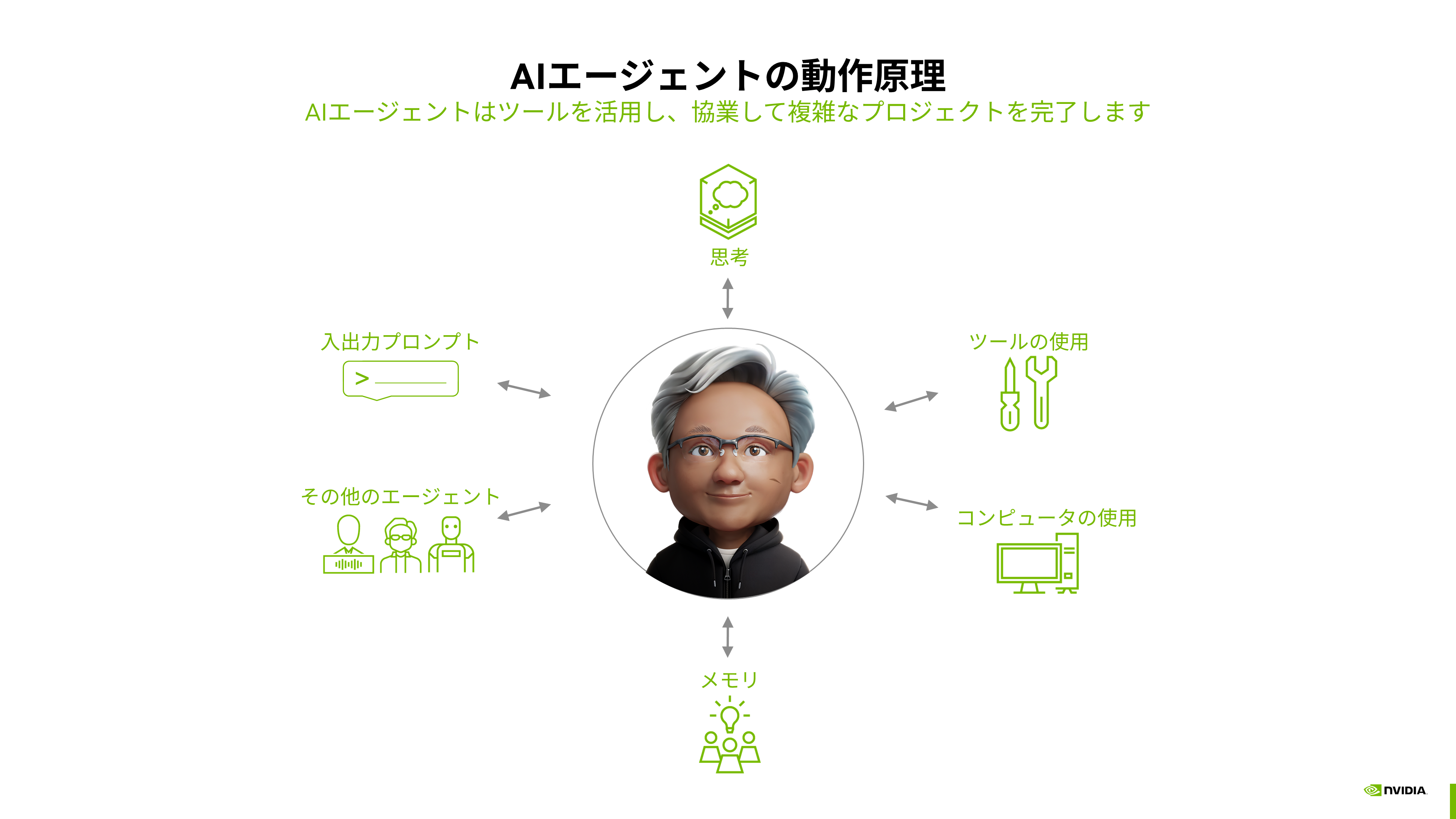
図表2:エージェントAIの動作原理
■リーズニングモデルの特徴
従来のLLMが出力する回答は、「知識」をベースとしています。例えば、「NVIDIAとは何か」という問いに対して、Wikipediaに書かれているような説明が回答として得られるわけです。
一方、リーズニングモデルは「思考」を行います。図表3に挙げた例題は、8人の家族が円卓で食事をする際に、それぞれの役割や人間関係を加味して席順を決めようというものですが、実はこのような問題は従来のLLMでは解決できません。複雑な制約や条件を理解し、きちんと思考した上で回答できるというのがリーズニングモデルの非常に大きな特徴となっています。
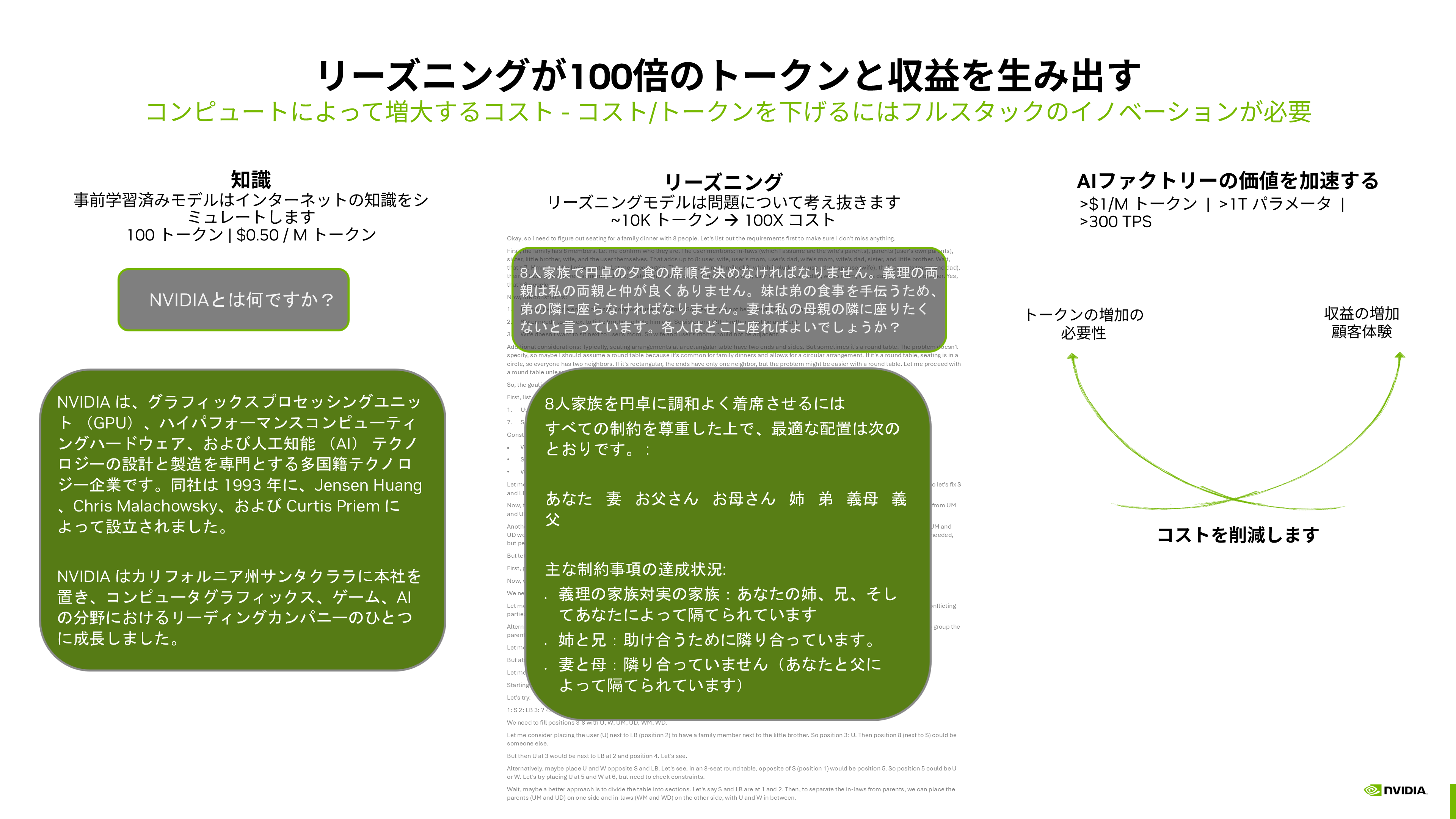
図表3:従来のLLMとリーズニングモデルの違い
では、リーズニングモデルを作るためにはどのぐらいの追加学習が必要なのでしょうか。仮に1兆パラメータのモデルを使った場合を考えてみましょう。まず100種類のトピック(主題テーマ)に関連した知識と、一つのトピックに対して約100万の質問を与えます。それに対して約100種類の回答候補があり、回答のそれぞれが約1万トークンで構成されるという想定です。
100トピック×100万質問×100回答×10,000トークン=100兆トークン
これで換算すると、学習に使うデータトークンは実に100兆に達し、これはLlama3の事前学習の約7倍に相当します。さらに、実際には1回の推論だけでは回答の精度が足りないことも多く、この場合は一度生成された回答を再びリーズニングモデルに与えるというプロセスを繰り返すことになります。このように、リーズニングモデルの作成と学習には、莫大なコンピューティングパワーが必要になるのです。
■NVDIAが提供するエージェントAI向けツール
「AI-Q NVIDIA Blueprint」はエージェントAIの開発を支援するツールセットで、以下のようなコンポーネントで構成されます。
・Llama Nemotron
Llamaをベースに高い精度と高速処理を実現したNVIDIA独自のリーズニングモデルで、Hugging Face※1で精度ナンバーワンの評価を得ています。
※1:AIモデルやデータセット、開発ツールを共有できる世界最大級のオープンソースプラットフォーム
・NeMo Retriever
エージェントAIによるRAGの活用を支援します。類似ソフトウェアに対して約15倍のデータ抽出速度と、約1.5倍の検索精度を持っています。
・NeMo Agent Toolkit
エージェントAIシステムを構築する際の性能評価や、ツールの登録などを管理するツールキットです。
■エージェントAIの活用例
「VSS(Video Search and Summarization)」はBlueprintの一つで、動画分析用のエージェントAIです。アーカイブもしくはストリーミングで取得した動画をエージェントAIが分析し、要約やQ&A、アラートを出力します。VLM(Vision Language Model)や物体認識を行うコンピュータビジョン、LLM、RAGなどのMINとグラフデータベース、ベクトルデータベースなどで構成されています。(図表4)
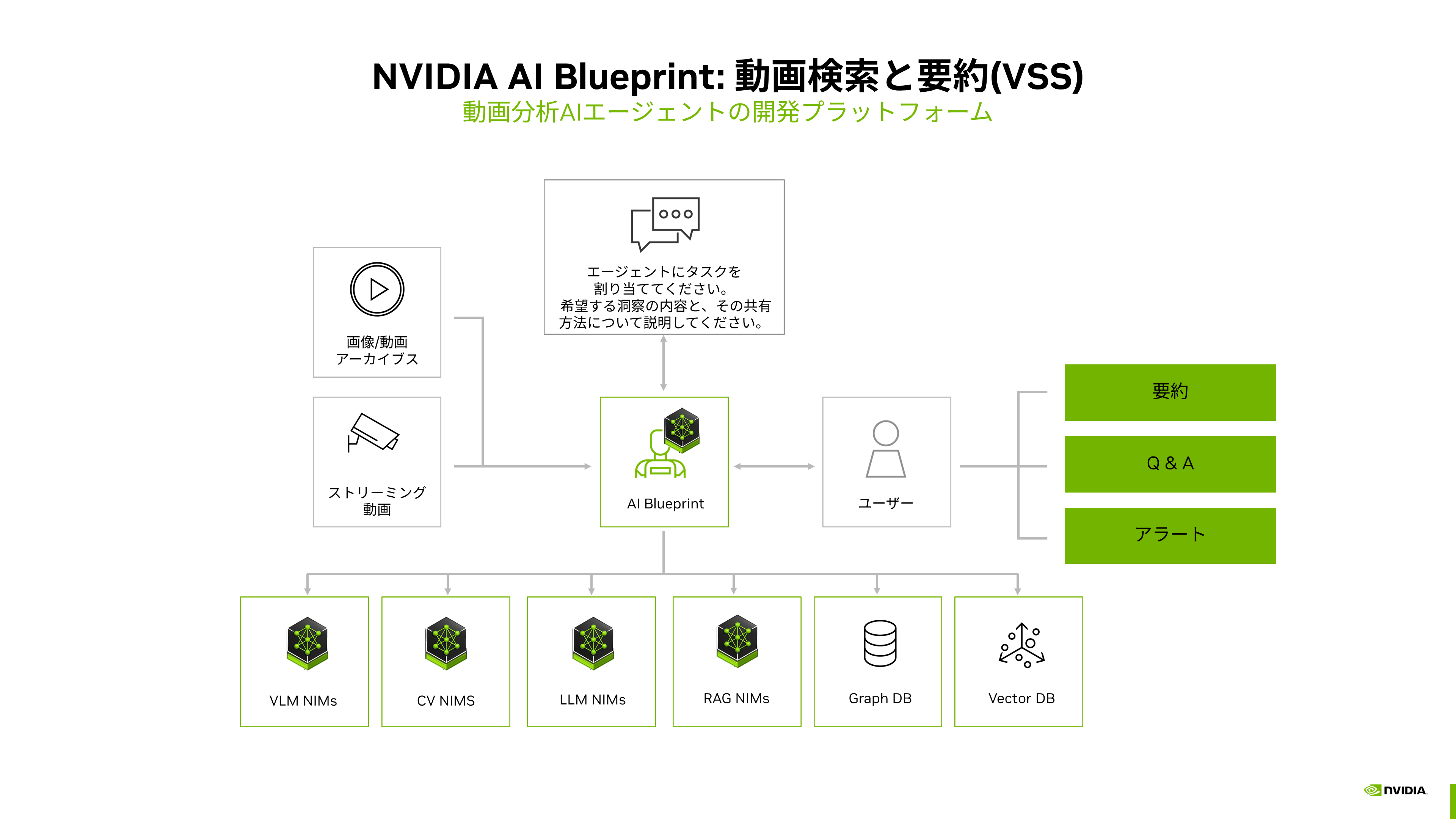
図表4:VSSの構成
VSSは、台湾に本社を置くPEGATRONという会社で実際の現場に投入されています。ここでは世界中のさまざまな企業からPCやスマートフォンなどの機器の組み立てを受注していますが、生産ラインが頻繁に変更されるため、作業員が工程・手順を間違う可能性があります。これをVSSによって監視・管理し、作業ミスの検出や改善に役立てています。
■フィジカルAIの実現に向けて
エージェントAIがこのまま順当に進化するなら、次に期待されるのはフィジカルAIの実現です。フィジカルAIの最大の特徴は、出力されるのがアクションのトークンである点で、これに必要となるのが「世界モデル」です。例えば、歩行ロボットが目の前にあるテーブルを迂回して移動するといったように、外部世界の物理的な現象を正確に理解して行動する能力が求められます。
物理現象の学習には当然データが必要になりますが、実世界のデータの取得はデジタルよりはるかにコストがかかります。また、ロボットの作成や物理的なテストはそれだけでも高コストですが、万一失敗した場合は修理費用がかかる上、危険を伴う可能性もあります。
こうした課題を克服するため、NVIDIAでは仮想空間活用したソリューションを展開しています。そこではテストやデータ収集、シミュレーションを可能とする世界モデル(NVIDIA Omniverse with Cosmos)が動作します。これに加えて事前学習と追加学習のコンピューティング(NVIDIA DGX)、そして実際にロボットに搭載して動かすランタイム環境(NVIDIA AGX)によって構成される三種類のコンピュータが相互にフィードバックしながら精度の向上を図っています(図表5)。
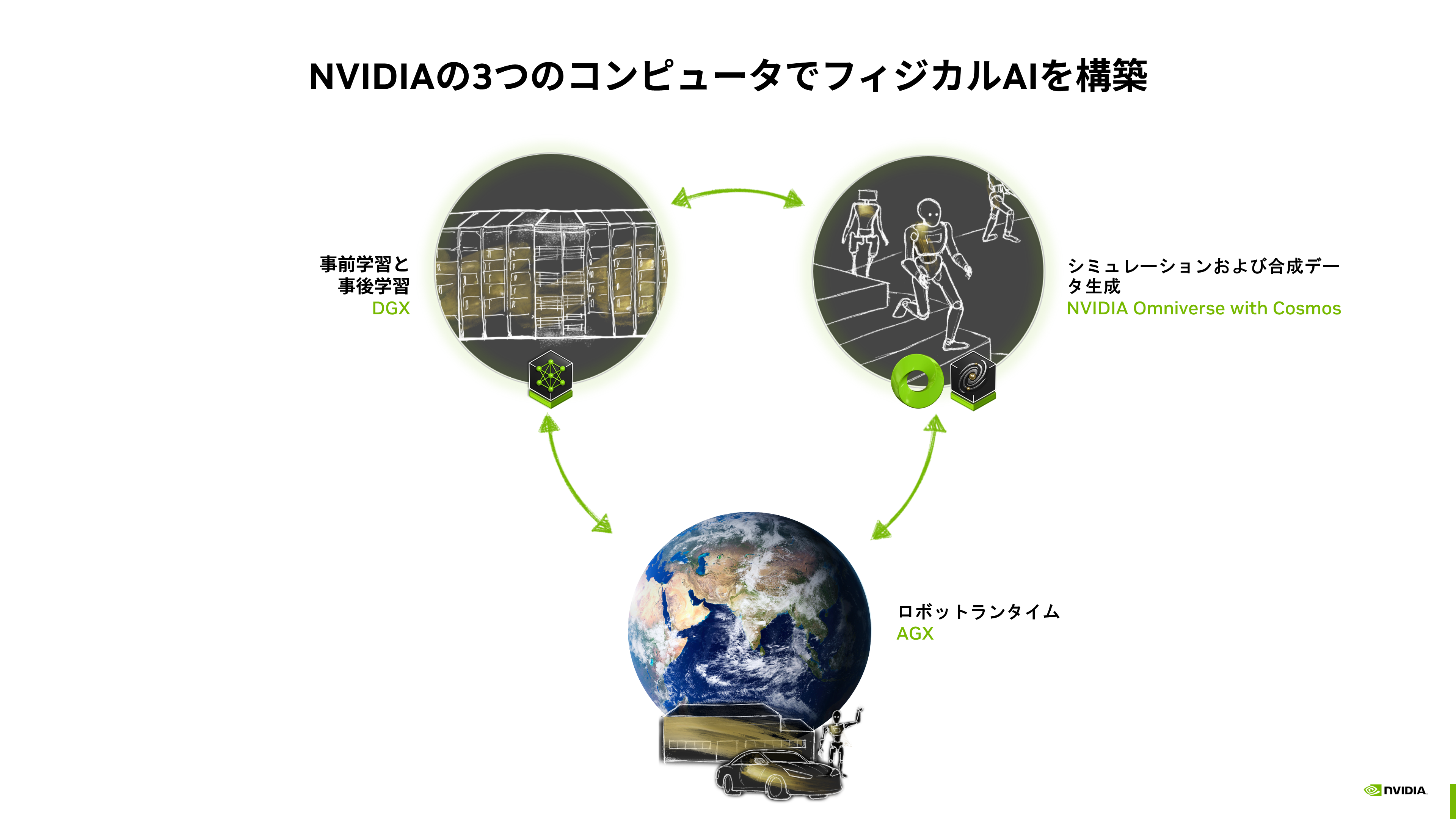
図表5:フィジカルAIを構築するNVIDIAの三つのコンピュータ
このソリューションによって開発されたヒューマノイドロボットの汎用的な基盤モデルが「NVIDIA Isaac GROOT N1」です。GROOT N1は人間の認知処理の原理にヒントを得た、高速思考と低速思考のデュアルシステムアーキテクチャを備えています。低速思考システムは環境と指示を認識・思考して適切なアクションを計画し、これを高速思考システムが正確で継続的なアクションに変換します。
現在、GROOTはバージョンアップ版のN1.5がHugging Faceで公開されており、誰でも自由に使える状態になっています。追加学習によるカスタマイズも可能なので、フィジカルAIの研究に大いに役立つはずです。
自動車業界におけるAIの活用
NVIDIAのAI技術は、自動車業界でもさまざまな形で活用が進んでいます。例えば、自動運転の開発では、状況の把握から思考、判断、行動までを制御するリーズニングとフィジカルAIの技術が利用できます。また、作成した自動運転用ソフトウェアを検証する際にも、デジタルツイン環境を利用したテストやシミュレーションが可能です。
さらに、エージェントAIはクルマのユーザー体験を変革する多様な可能性を秘めています。例えば、AIアシスタントは、ドライバーと会話をしながら目的地までの安全で快適な運転をサポートする他、自動運転のパイロットやインターネットを活用した旅行ガイド、エンターテインメント、整備士など、さまざまなエージェントの利用シーンが考えられます。これらは外部ツールとしてホテルの予約サイトやオフィスアプリ、SMSなどを活用して、クルマとその利用環境をより快適にしていくことが期待されています(図表6)。
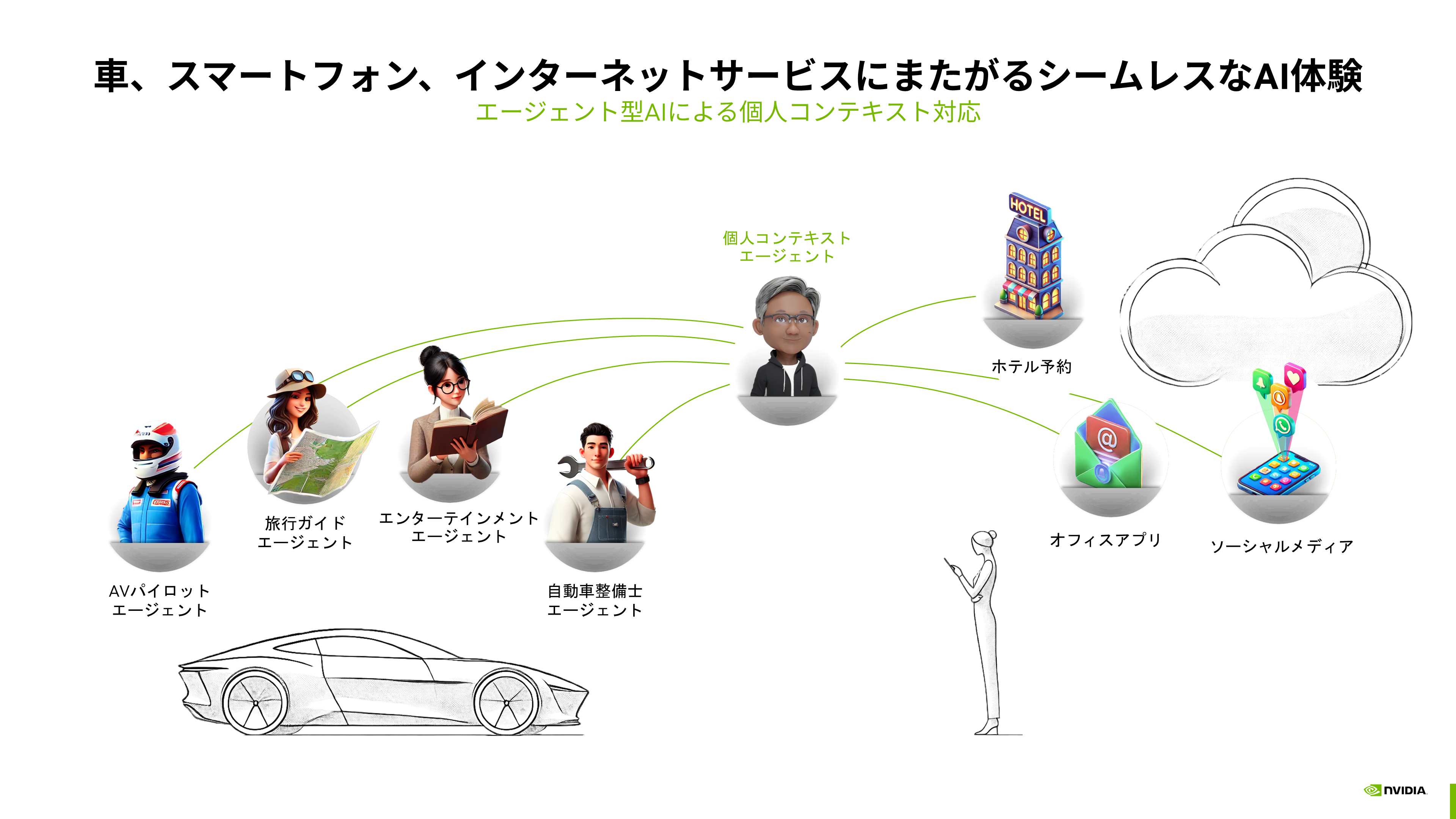
図表6:エージェント型AIで実現する新たなクルマの利用環境
おわりに
生成AIとその後に続くエージェントAI、フィジカルAIの可能性についてお話ししました。ご紹介したNVIDIAのソリューションは、オープンソースもしくは無料で試用が可能なものも多くありますので、ぜひ生成AIの持つ能力と可能性を体験し、今後の研究開発にお役立てください。
掲載されている製品名、会社名、サービス名は、各社の商標または登録商標です。
この記事をシェアする